

ณภัทร จาตุศรีพิทักษ์

ที่มาภาพ : https://pantip.com/topic/35973668
เคยคิดไหมครับว่าชีวิตและสังคมของพวกเราจะเปลี่ยนไปแค่ไหนหากวันนึงเราทุกคนมี social credit score หรือ “คะแนนทางสังคม” ที่ปรับขึ้นลงตามทุกๆ พฤติกรรมของเรา
ทำตัวดี เป็นมิตร ไม่หลอกลวง ไม่หยาบคาย คะแนนขึ้น

ทำตัวชั่ว เห็นแก่ตัว เป็นมนุษย์ป้า เกียจคร้าน คะแนนลง
พูดง่ายๆ ก็คือเราจะมีคะแนนหรือดาวไม่ต่างจากที่ร้านอาหารมีคะแนนใน Wongnai หรือที่คนขับรถและผู้โดยสารมีคะแนนใน Uber
แต่คะแนนนี้ไม่ได้แค่กระทบจำนวนลูกค้าที่จะมาร้านอาหารเรา หรือโอกาสที่เราจะได้ไปแมทช์กับคนขับที่คุณภาพดีเท่านั้น…

มันเป็นไปได้ว่าคะแนนที่ว่านี้สามารถกระทบได้แทบทุกมิติของชีวิตเรา ตั้งแต่เกิดแก่เจ็บตาย และอาจถูกใช้เป็นตัวกำหนดสิทธิว่าใครสามารถอยู่อาศัยในแต่ละท้องที่ได้ ใครจะใช้รถไฟฟ้าได้ ใครจะใช้ทางด่วนได้ในชั่วโมงเร่งด่วน ใครจะได้รับการรักษาพยาบาล ใครจะเอาลูกเข้าโรงเรียนดีๆ
ที่สำคัญคือผู้เขียนคิดว่านี่จะไม่ใช่สิ่งที่อยู่ในแค่นิยาย ที่เป็นโลก distopian ฟีลฝันร้ายแบบในทีวีซีรีส์เรื่อง Black Mirror ตอน Nosedive เท่านั้น สิ่งที่เรากำลังพูดถึงอยู่นี้มีให้สมัครใช้แล้วในประเทศจีน และทางการจีนจะมีการบังคับใช้มันกับประชาชนจีนทั้งหมดภายในปี 2020 โดยคะแนนประชาชนนี้จะถูกสังเคราะห์ขึ้นมาจาก Big Data จากข้อมูลถังใหญ่ๆ หลายๆ ถังรวมกัน

หากมันเกิดขึ้นในประเทศจีน และได้รับการยอมรับพอสมควร ก็คงไม่ช้าที่จะมีการเริ่มใช้ระบบคะแนนทางสังคม (หรือรูปแบบอื่นๆ ของมัน) ในประเทศอื่นๆ
ทุกครั้งที่คุณแชท ทุกสเตตัสที่อัป ทุกครั้งที่จ่ายบิลตรงเวลา ทุกครั้งที่ซื้อสุรา ทุกครั้งที่สุงสิงกับเพื่อนที่ไม่เอาไหน ทุกครั้งที่จ่ายภาษีครบถ้วน ทุกครั้งที่บริจาคเลือด ทุกการเคลื่อนไหวของคุณ ถ้ามี digital footprint มากพอ ในอนาคตอาจถูกเอามาสังเคราะห์เป็นคะแนนดังกล่าวได้
บทความนี้จะขอไม่เน้นถึงความมืดและความน่ากลัวของคะแนนทางสังคม แบบที่เห็นกันในเรื่อง Black Mirror เพราะผู้เขียนคิดว่ามันน่าจะเป็นสิ่งที่หลายคนมองเห็นได้ตั้งแต่อ่านย่อหน้าแรกของบทความนี้แล้ว อีกทั้งยังเป็นประเด็นที่ถูกหยิบขึ้นมาวิพากษ์วิจารณ์กันมากแล้ว
บทความนี้จึงจะพูดถึง “ความเทา” ของการใช้ Big Data ในมิตินี้แทน จะลองวิเคราะห์ดูว่าภายใต้ความมืดของความคิดคะแนนทางสังคมนี้ยังพอมีแสงสว่างบ้างหรือไม่ ถ้าเราตั้งใจทำให้มันดีต่อสังคมจริงๆ เราทำได้ไหม มีความเป็นไปได้แค่ไหนที่สังคมที่มีระบบนี้จะดีกว่าสังคมที่เป็นอยู่ทุกวันนี้ ถ้าเป็นไปได้เราจะต้องทำอย่างไรบ้างและอะไรคืออุปสรรค
นี่เป็นคำถามที่ควรตอบให้ได้ก่อนเพื่อน เนื่องจากโทษของการมีระบบนี้มันชัดเจน (การรุกล้ำความเป็นส่วนตัวของประชาชน ความผิดเพี้ยนของความสัมพันธ์ฉันเพื่อน ฯลฯ) แต่ประโยชน์อาจต้องตั้งใจคิดนิดหนึ่ง
ผู้เขียนมองว่าระบบคะแนนประชาชนสามารถเป็นเครื่องมือเชิงนโยบาย (policy lever) เพื่อขจัดความล้มเหลวของตลาด (market failure) ได้ แบบเดียวกับที่ ภาษี การอุดหนุน และกฎหมายอื่นๆ กำลังหล่อหลอมผลักดันทิศทางและผลลัพธ์ทางเศรษฐกิจและสังคมอยู่ทุกวันนี้
การเชื่อมคะแนนนี้เข้ากับแรงจูงใจหรือบทลงโทษที่คนแคร์พอ จะเป็นเหมือนการ “บังคับแบบอ้อมๆ” ให้คนเราประพฤติคล้อยตามแนวทางที่รัฐวางไว้
ไม่ต่างกับการเก็บภาษีสุราบุหรี่เพื่อโน้มน้าวให้คนลดการบริโภคสินค้าที่มีโทษต่อตนเองและผู้อื่น หรือการอุดหนุนค่าวัคซีนเพื่อลดการแพร่เชื้อในสังคม
ยิ่งคะแนนทางสังคมถูกเชื่อมกับสิ่งที่จำเป็นต่อชีวิตและสิ่งที่ชอบหรือไม่ชอบมากๆ เท่าไหร่ คะแนนนี้จะยิ่งเป็นสินทรัพย์ที่มีคุณค่ามากเท่านั้น (จึงจะไม่แปลกใจเลยหากวันหนึ่งจะเกิดอาชีพที่ปรึกษาคะแนนทางสังคมเหมือนในซีรีส์เรื่อง Black Mirror)
ขณะนี้คงยังเร็วไปที่จะฟันธงว่าระบบนี้กับเครื่องมือเชิงนโยบายอื่นๆ แบบไหนจะมีประสิทธิภาพเชิงในเศรษฐกิจมากกว่ากัน แต่ผู้เขียนมองว่าประโยชน์ของระบบนี้จะขึ้นอยู่กับสองปัจจัยต่อไปนี้
หนึ่ง สังคมที่มีปัญหาเรื่องความไว้วางใจ (trust) น่าจะได้รับประโยชน์จากระบบนี้มากกว่าสังคมอื่น
ความไว้วางใจระหว่างบุคคล ระหว่างธุรกิจ เป็นส่วนผสมสำคัญของความเจริญและความมีประสิทธิภาพของเศรษฐกิจ ใครเคยทำธุรกิจในประเทศจีนหรือนำเข้าส่งออกผ่านประเทศจีน ก็คงทราบดีว่าทำไม
หากมีคนคดโกง มีของปลอม มีการหลอกลวงอยู่เป็นประจำ การทำธุรกิจ การเริ่มต้นความสัมพันธ์ หรือแม้กระทั่งการใช้ชีวิตประจำวันอย่างการวางกระเป๋าไว้บนโต๊ะตอนไปห้องน้ำโดยไม่ต้องกลัวคนขโมย จะกลายเป็นว่ามันมี “ต้นทุนความไม่ไว้วางใจ” ติดมาทุกๆ ครั้งที่ทำกิจกรรมเหล่านี้โดยพยายามให้เราไม่เสียประโยชน์ เช่น ค่าจ้าง law firm เวลาที่เสียไปกับการสืบประวัติคู่ค้า หรือความไม่สะดวกอื่นๆ ซึ่งรวมๆ ทั้งสังคมแล้วจะเป็นเงินและเวลาอันมหาศาล
จึงไม่แปลกที่จีนเป็นสังคมแรกที่จะเริ่มใช้ระบบคะแนนทางสังคมนี้ หากคะแนนสามารถสะท้อนความไว้วางใจได้ดีจริง ประชาชนจะทำอะไรก็สะดวก เพียงมีเทคโนโลยีตรวจสอบตัวเลขตัวเดียวของคู่ค้า (หรือคู่รัก!) ว่ามันสูงพอที่เราจะทำการค้าหรือจะมีปฏิสัมพันธ์ด้วยไหมก็พอ
พูดง่ายๆ ว่ามันจะช่วยลด transaction cost อันมหาศาลลงได้
สอง สังคมที่ไม่สามารถบังคับใช้กฎหมายได้อย่างจริงจังหรือมีปัญหาความไม่เท่าเทียมกันควรเหลียวตามองระบบนี้เป็นอย่างน้อย โดยเฉพาะปัญหาสาธารณะในมิติที่รัฐเองไม่มีกำลังตรวจสอบ หรือไม่คุ้มที่จะเจียดทรัพยากรไปแก้ปัญหา (ทั้งๆ ที่จริงก็ควรทำแต่อาจทรัพยากรไม่พอจริงๆ) ยกตัวอย่าง เช่น การร้องเรียนเรื่องเพื่อนบ้านที่ไม่เคารพกฎหมาย ไม่ว่าจะเป็นการส่งเสียงดังรบกวน ทิ้งขยะและจอดรถเขวี้ยงขว้าง ซึ่งแม้มันเป็นปัญหาขนาดเล็กเมื่อเทียบกับปัญหาสังคมอื่นๆ เช่น อาชญากรรม หรือการค้ายาเสพติด แต่รวมๆ ทั้งประเทศแล้วมันเป็นปัญหาที่กระทบความเป็นอยู่ของคนจำนวนมาก ระบบคะแนนทางสังคมอาจช่วยผ่อนเบาภาระในจุดนี้ได้
ผู้เขียนไม่คิดว่าระบบนี้จะมาช่วยจัดระเบียบบ้านเมืองได้หมด โดยเฉพาะอย่างยิ่งในสังคมที่ไม่ค่อยมีใครทำตามระเบียบอยู่แล้ว แต่อย่างน้อยก็ควรสำรวจดูว่าเทคโนโลยีนี้สามารถทำให้อะไรๆ มันลงล็อก เป็นระเบียบได้โดยการจูงใจ
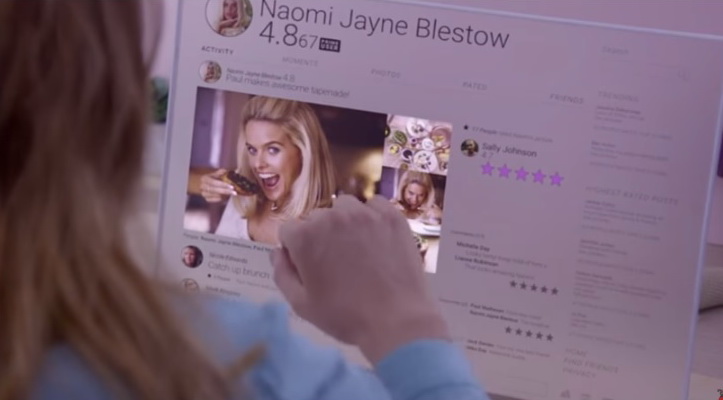
ที่มาภาพ : https://www.youtube.com/watch?v=a8tX9zjO698
สมมุติว่าเราคิดว่าน่าจะทดลองนำร่องใช้ไอเดียนี้ เรามาปูพื้นคอนเซปต์แบบง่ายๆ ก่อนว่า การที่คนคนหนึ่งจะมีคะแนนเท่านั้นเท่านี้ มันมีที่มาจากอะไร ต้องมีอะไรเป็นวัตถุดิบ
อันดับแรกที่จำเป็นคือสังคมจะต้องตกลง (จะโหวตหรือจะถูกบังคับก็แล้วแต่ดีกรีความเป็นเผด็จการในสังคม) กันให้ได้ว่า อะไรคือ “ความเป็นประชาชนที่ดี” ใครคือประชาชนในอุดมคติ (ideal citizen) เช่น เป็นคนที่จ่ายบิลตรงเวลา เป็นคนที่ไม่พูดหยาบคายหรือไม่ปล่อยและไม่แชร์ข่าวปลอมบนโลกโซเชียล เป็นต้น ขอเรียกลักษณะเหล่านี้ว่า “ลักษณะในอุดมคติ”
อันดับที่สอง คือ สังคมจะต้องมีความสามารถในการสังเกตการณ์ว่าประชาชนมีพฤติกรรมที่สะท้อนลักษณะในอุดมคติเหล่านั้นมากน้อยแค่ไหน ฉะนั้น ยิ่งข้อมูลใหญ่ กว้าง ลึก และถี่เท่าไร ยิ่งมีโอกาสทำให้ภาพสเก็ตช์ของ “ประชาชนในอุดมคติ” ชัดเจนขึ้น
ปัจจุบันอาจสังเกตการณ์ประชาชนได้แค่ 20 มิติ แต่ในอนาคตแห่ง IoT (Internet of Things) ที่แทบทุกพฤติกรรมของเราจะมี digital footprint สังคมอาจสังเกตการณ์ประชาชนได้ทุกๆ ย่างก้าวแม้แต่สิ่งที่เขากำลังคิดในใจวันหนึ่งก็เป็นไปได้
มีสองปัจจัยดังกล่าวไม่พอ สังคมยังมีทางเลือกในทางปฏิบัติอีกมากมายว่าจะสังเคราะห์คะแนนทางสังคมออกมาด้วยวิธีใด
หนึ่งทางเลือกที่เป็นไปได้คือการออกไปหากลุ่มคนในอุดมคติจริงๆ มากลุ่มหนึ่ง และให้จำแนกว่าพวกเขาเป็น “คนดี” (ตัวแปร good_citizen = 1 สำหรับคนกลุ่มนี้ ส่วนที่เหลือ good_citizen = 0) แล้วจึงค่อยให้ระบบเฟ้นหาลักษณะที่มีความสามารถในการพยากรณ์ “ความน่าจะเป็นคนดีของสังคม” โดยจะใช้เทคนิคทางสถิติใดๆ ก็ตามแต่ ซึ่งท้ายสุดแล้วเราจะได้ สูตรคะแนนสังคมที่มีหน้าตาเป็นสมการประมาณนี้:
คะแนนทางสังคม = 0.24*1[เคยไปบริจาคเลือดใน6เดือนที่ผ่านมา] -0.8*จำนวนบิลที่จ่ายช้าในปีที่ผ่านมา + 0.42*คะแนนเอนทรานซ์ -0.28*จำนวนใบสั่งในช่วง 2 เดือนที่ผ่านมา +…
ซึ่งสมการตัวอย่างด้านบนนี้เป็น approach ที่ data driven โดยมีรัฐเป็นผู้ supervise
อีกทางเลือกคือการกำหนดสูตรแต่แรกเลยว่าพฤติกรรมไหนควรได้รับน้ำหนักเท่าไร เช่น ขับรถขณะมึนเมาทุกครั้งคะแนนลดลง 100 คะแนน หรือมาประชุมและเลิกประชุมตรงเวลาทุกครั้งรับไป 30 คะแนน
แตกต่างกับทางเลือกที่แล้วเนื่องจากรัฐเป็นผู้เลือกโดยตรงว่าพฤติกรรมไหนควรจะมีความสำคัญต่อคะแนนทางสังคมมากน้อยตามลำดับ
โดยส่วนตัว ผู้เขียนคิดว่าทั้งสองทางเลือกมีทั้งข้อดีข้อเสีย ข้อดีของทางเลือกแรกคือเราจะลดอคติในการให้น้ำหนักแต่ละพฤติกรรมน้อยลง แต่ในขณะเดียวกันก็มีข้อเสียตรงที่ว่าเราจะไปเลือกกลุ่มตัวอย่างที่เป็นประชาชนดีเด่นอย่างไรให้ไม่ลำเอียง
ทางเลือกที่น่าจะ practical ที่สุดคงจะเป็นการ blend ทั้งสองทางเลือกเข้าด้วยกันเพื่อให้รัฐพอจะมีพื้นที่ในการชักจูงพฤติกรรมใหม่ๆ ได้ โดยไม่ลำเอียงมากนัก
ผู้เขียนเชื่อว่าถ้าวันหนึ่งมีการเชื่อมต่อถังข้อมูลกันจริงๆ งานสร้างคะแนน ไม่ว่าจะด้วยเทคนิคทางเศรษฐมิติ machine learning หรือแค่ผูกสูตรตรงๆ เพื่อให้คะแนนสะท้อนความดีงามอย่างแม่นยำนั้น ไม่ใช่จุดที่ยากที่สุด
จุดที่ยากที่สุดคือเรื่องของจริยธรรมและการบริหารระบบนี้อย่างเป็นธรรม
ผู้เขียนขอส่งท้ายบทความนี้ด้วยคำถามให้ผู้อ่านเก็บไปคิดกันในเวลาว่าง เพราะหากเราจะมาทางนี้ในอีกสิบยี่สิบปี ยังไงเราก็หนีไม่พ้นคำถามต่อไปนี้
หนึ่ง สูตรควรจะโปร่งใสและอ่อนไหวแค่ไหน ที่สูตรไม่ควรโปร่งใส 100% และอ่อนไหวต่อทุกพฤติกรรมเกินไป เป็นเพราะว่าเราไม่ต้องการให้คนบางกลุ่มหาทางลัด หาวิธี fake พฤติกรรมขึ้นมาเพื่อหลอกแบบจำลองของเรา (พยายามทำพฤติกรรมออนไลน์ให้ได้คะแนนสูง ทั้งๆ ที่พฤติกรรมออฟไลน์จริงๆ แล้วไม่ดี) และเราไม่ต้องการให้ประชาชนวิตกจริตกับคะแนนนี้จนกระทั่งสังคมเราไม่น่าอยู่ หรือกลายเป็นว่าระบบนี้จูงใจได้รุนแรงถึงขั้นที่พวกเราเริ่มสูญเสียความเป็นเอกลักษณ์ของตนเอง ทุกคนพยายามทำตัว “ดี” จนกลายเป็น carbon copy ของประชาชนในอุดมคติที่รัฐเชิดชูกันทั้งบ้านทั้งเมือง
สอง ใครจะมีอำนาจในการพัฒนาสูตรของคะแนนนี้ เรายังไปไม่ถึงยุคที่ AI ชี้ชะตาคะแนนทางสังคมได้ 100% (และอาจเป็นเรื่องที่มนุษย์ควรทำกันเอง) และมีแนวโน้มว่าบางส่วนของสูตรมีโอกาสถูกปิดเป็นความลับ (เนื่องด้วยประเด็นแรก) ดังนั้น บุคคลกลุ่มนี้จะได้เปรียบกลุ่มอื่นมาก พวกเขาจะทราบถึง “สูตรเด็ด” ในการยกระดับชีวิตในโลกใบใหม่
เท่านั้นไม่พอ การที่คะแนนทางสังคมจะมาเป็น currency ใหม่ที่สำคัญเยี่ยงชีพนั้นจะยิ่งทำให้มันเป็นเป้าต่อการใช้เส้นสาย หรือการปรับสูตร (หรือแก้ตัวเลขดื้อๆ) เพื่อให้พรรคพวกได้ประโยชน์
แต่หากเราไม่ให้อำนาจทีมนี้ และหันมาทำการโหวตน้ำหนักทีละตัวแปรในแบบจำลองสถิติ มันก็ไม่ใช่อะไรที่คนทั่วไปจะสนใจหรือจะเข้าใจแบบลึกซึ้งได้ จะให้ democratize การให้คะแนนแบบในเรื่อง Black Mirror ที่เราสามารถเพิ่มหรือลดคะแนนกับทุกคนที่เราพบหน้าก็มีความเสี่ยงต่อการล่มสลายของสังคม
จะเห็นได้ว่าการใช้ Big Data ในการสร้างระบบคะแนนทางสังคมจึงมี “ความเทา” อยู่พอสมควร ในมุมมองหนึ่ง มันมีด้านมืดของการละเมิดความเป็นส่วนตัวและการจำกัดวิถีชีวิตคนเรา แต่ในอีกมุมมอง มันก็มีด้านสว่างที่เป็นความหวังในการเพิ่มประสิทธิภาพในการบริหารสังคม ลดความล้มเหลวของตลาด และเพิ่มความโปร่งใสในการจัดการทรัพยาการว่าใครควรจะได้อะไร ใครควรจะอด
ผู้เขียนหวังว่าท่านผู้อ่านจะได้ลิ้มรสชาติของแนวคิดนี้ และจะได้มีโอกาสไปลองจินตนาการว่าถ้าจะทำระบบนี้ในบ้านเรา เราควรทำอย่างไร คิดอย่างไรก็อย่าลืมแชร์ อย่าลืมถกเถียงกันครับ

