ณภัทร จาตุศรีพิทักษ์
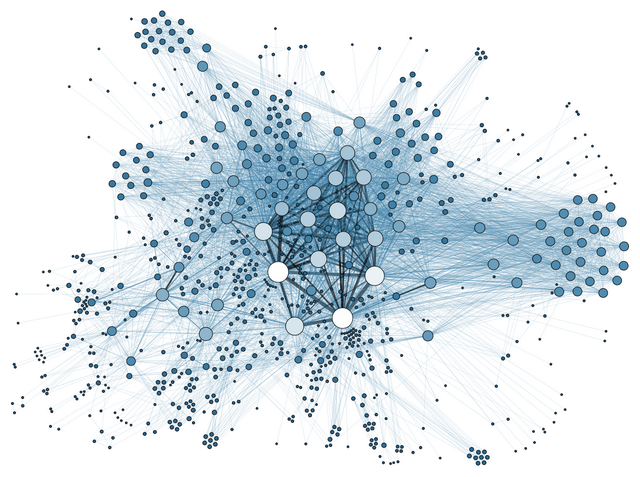
จากวินาทีที่คุณเปิดเว็บเบราว์เซอร์ โหลดหน้าเว็บไซต์นี้ อ่านหัวข้อบทความนี้ มองภาพประกอบด้านบน และอ่านประโยคแรกตั้งแต่ต้นจนมาถึงจุดนี้ โดยเฉลี่ยแล้วมีการประเมินไว้ว่าจะมีมนุษย์โลกแชร์เรื่องราวใน facebook ไปแล้วกว่า 2.5 ล้านครั้ง เสิร์ชกูเกิลไปแล้วกว่า 4 ล้านครั้ง บริษัท Amazon จะทำยอดขายไปได้แล้ว 8 หมื่นเหรียญดอลลาร์สหรัฐ และมีการส่งอีเมลไปแล้วราว 200 ล้านอีเมล
ในปี ค.ศ. 2012 สังคมมนุษย์มีการผลิตข้อมูลมากถึงวันละ 2.5 quintillionไบท์ (หรือเขียนให้เห็นภาพขึ้นคือเท่ากับ 2,500,000,000,000,000,000 ไบท์)
นี่คือโลกปัจจุบันที่ทุกๆ นาทีจะมีการกำเนิดของข้อมูลจำนวนมหาศาลที่สามารถถ่ายทอดเรื่องราวชีวิตและพฤติกรรมของมนุษย์ได้ด้วยความละเอียดและหลากมิติอย่างที่เราไม่เคยคิดว่าเป็นไปได้มาก่อน ทุกวันนี้บริษัทเล็กใหญ่ต่างใช้ประโยชน์จากข้อมูลเหล่านี้เพื่อการตลาดและการพัฒนาผลิตภัณฑ์และบริการเพื่อการแสวงหากำไร
แต่ทว่า Big Data ที่กำลังเป็นที่ตื่นตาตื่นใจในมิตินี้ ผมคิดว่ามันกลายเป็นเรื่องน่าเบื่อไปเลยเมื่อเอาไปเทียบกับสิ่งที่กำลังจะมาแรงในอนาคตที่เขาเรียกกันว่าปรากฏการณ์ “Open Data”
ก้าวสำคัญต่อไปของ Big Data คือสิ่งที่เรียกว่า Open Data ซึ่งเป็นภาวะที่อภิมหาข้อมูลสาธารณะของสิ่งต่างๆ ที่เกิดขึ้นรอบตัวคุณจะกลายเป็นสมบัติของประชาชนทุกหมู่เหล่า เอาไปใช้สอยได้ตามอัธยาศัยโดยประชาชนและเพื่อประโยชน์ของประชาชน
บทความนี้จะยกตัวอย่างแนวทางหลากหลายในการใช้ Big Data เพื่อแก้ปัญหาตั้งแต่ปัญหาธุรกิจ เช่น ทำอย่างไรจึงได้คั้นกำไรออกมาให้ได้ทุกหยดจากกระเป๋าสตางค์ลูกค้าไปจนถึงปัญหาสังคม เช่น การปราบปรามอาชญากรรม และชี้ให้เห็นถึงความน่าตื่นเต้นยิ่งกว่าของปรากฏการณ์ Open Data ที่จะนำมาสู่ความเป็นไปได้อันไร้ขีดจำกัดในการพัฒนาสังคมมนุษย์
เนื่องจากบทความนี้ยาวเป็นพิเศษ จึงขอเสนอสารบัญย่อๆ ด้านล่างดังนี้ (หากผู้อ่านคุ้นเคยกับ Big Data แล้ว ข้ามไปอ่านข้อ 5 ได้เลย)
- Big Data เพื่อการหาลูกค้า
- Big Data เพื่อการ “คั้น” กำไร
- Big Data เพื่อการสัญจรและอนาคตของป้ายโฆษณา
- Big Data ของข่าวสารและเหตุการณ์ทั่วโลก
- สัมผัสกับโลกของ Open Data
- ประโยชน์อันมหาศาลของ Open Data
- รัฐบาลได้อะไรจาก Open Data
- อนาคตของ Open Data ขึ้นอยู่กับพวกเราเอง
กรณีศึกษาสุดคลาสสิก: Big Data เพื่อการหาลูกค้า

ที่จริงแล้วในโลกธุรกิจนั้น Big Data ไม่ใช่อะไรใหม่เลย บริษัทสตรีมภาพยนตร์และละครทีวีชื่อดัง Netflix นั้นใช้ข้อมูลพฤติกรรมลูกค้าเพื่อแนะนำรายการทีวีและภาพยนต์ที่ลูกค้าน่าจะชอบมากที่สุดเพื่อเพิ่มโอกาสในการสร้างยอดขาย ห้างสรรพสินค้าชื่อดังอย่าง Saks Fifth Avenue นั้นก็ใช้ข้อมูลมหาศาลเพื่อเสนอสินค้าและหน้าตาของเว็บไซต์ที่แตกต่างออกไปตามประเภทของลูกค้าและพบว่าลูกค้าที่ใช้บริการทั้งทางดิจิทัลและทางหน้าร้านโดยเฉลี่ยแล้วจะใช้เงินมากกว่าสองถึงสี่เท่าเลยทีเดียว
ตัวอย่างที่โด่งดังที่สุดในการใช้ข้อมูลเพื่อหาลูกค้าคงจะเป็นการที่บริษัทซูเปอร์มาร์เก็ตยักษ์ใหญ่ Target ใช้ข้อมูลพฤติกรรมช็อปปิ้งเพื่อทำการพยากรณ์ว่าลูกค้าเพศหญิงคนไหนกำลังตั้งครรภ์อยู่ ที่ทำเช่นนี้เพราะว่าลูกค้ากลุ่มนี้ถือว่าเป็น “เหมืองกำไร” ชั้นดี เนื่องจากว่าเป็นกลุ่มลูกค้าที่มีโอกาสที่จะทำการจับจ่ายใช้สอยสูงมากในอนาคตอันใกล้ แรกๆ อาจจะเป็นแค่ผ้าอ้อม จุกนม นมผง และเสื้อผ้าทารก แต่ไปๆ มาๆ หากติดใจการช็อปปิ้งที่ Target คุณแม่มือใหม่และสามีก็จะเริ่มซื้อผลิตภัณฑ์อีกหลายๆ อย่างที่มาพร้อมกับการมีบุตร เช่น ของเล่น หนังสือนิทานก่อนนอน สุดท้ายครอบครัวนี้อาจกลายเป็นลูกค้าประจำของ Target ไปเลยที่ทุกอาทิตย์จะเข้ามาซื้ออาหารและของใช้ในชีวิตประจำวัน ด้วยเหตุนี้ Target จึงต้องการแย่งลูกค้ากลุ่มนี้มาจากคู่แข่งให้เร็วที่สุด จึงทำการวิเคราะห์ข้อมูลว่าผู้หญิงที่กำลังตั้งครรภ์ในระยะแรกๆ มักมีพฤติกรรมการซื้อสินค้าประเภทไหนและบ่อยแค่ไหนจากซูเปอร์มาร์เก็ตของตน จากนั้นก็ทำการส่งใบปลิวโฆษณาหรือโปรโมชั่นพิเศษไปเพื่อที่จะมัดใจลูกค้ากลุ่มนี้ตั้งแต่คุณแม่เหล่านี้ “ยังไม่เป็นคุณแม่” เลยทีเดียว
Big Data เพื่อการคั้นกำไร

ปกติแล้วราคาของชาเขียวขวดหนึ่งในร้านหนึ่ง กับราคาของชาเขียวแบบเดียวกันในอีกร้านหนึ่งจะเท่ากัน แต่ในอนาคตอาจจะไม่เป็นอย่างนี้ก็เป็นได้
เหตุเนื่องมาจากการที่คนเรามีความเต็มใจที่จะจ่าย หรือที่นักเศรษฐศาสตร์เรียกกันว่า “willingness to pay” ไม่เท่ากัน
ยกตัวอย่างเช่น iPad รุ่นเดียวกัน ออกมาจากโรงงานเดียวกัน ขายเรียงกันบนชั้นเดียวกัน เหมือนกันทุกประการ แต่ลูกค้าบางคนมีความยินยอมที่จะซื้อด้วยราคาที่สูงต่ำกว่ากัน หากบริษัทมีข้อมูลพฤติกรรมการซื้อขายมากพอและสามารถแยกลูกค้าทุกคนออกตามระดับ willingness to pay ได้อย่างแม่นยำและสมบูรณ์ บริษัทเหล่านี้จะสามารถเก็บเกี่ยวกำไรได้อย่างมีประสิทธิภาพขึ้นโดยแทบไม่ต้องกระดิกนิ้วคิดค้นผลิตภัณฑ์ใหม่ๆ เลย
ตัวอย่างของบริษัทที่มีคนสงสัยว่าใช้กลยุทธ์นี้มีมากมาย เช่น
1. บริษัทรับจองตั๋วเครื่องบินและโรงแรม Orbitz ที่ถูกกล่าวหาว่าพยายามจูงใจให้ผู้ใช้คอมพิวเตอร์ Mac ไปจองโรงแรงหรือซื้อตั๋วประเภทที่มีราคาแพงกว่าปกติ เนื่องจากบริษัท Orbitz พบว่ากลุ่มผู้ใช้ Mac นั้นโดยเฉลี่ยแล้วซื้อสินค้าและบริการที่แพงกว่ากลุ่มผู้ใช้ PC กว่า 30%
2. บริษัทเครื่องเขียน Staples ตั้งราคาเครื่องเย็บกระดาษไม่เท่ากันในแต่ละท้องที่
3. บริษัทตกแต่งบ้าน Home Depot ดันราคาสินค้าขึ้นสำหรับลูกค้ากลุ่มที่ใช้โทรศัพท์มือถือเพื่อซื้อสินค้า
ในอนาคตนั้นหากข้อมูลพฤติกรรมการจับจ่ายใช้สอยมีมากขึ้นเรื่อยๆ และไม่มีกฎหมายห้ามพฤติกรรมอันชาญฉลาดของบริษัทเหล่านี้ ผู้บริโภคอย่างเราๆ คงตกเป็นเหยื่อของสิ่งที่นักเศรษฐศาสตร์เรียกกันว่า “First Degree Price Discrimination (FDPD)” อย่างแน่นอน โดยเฉพาะอย่างยิ่งสำหรับสินค้าชนิดที่ขายต่อลำบาก ในภาษามนุษย์นั้น FDPD คือ “การตั้งราคาเพื่อคุณและคุณเท่านั้น” ราคาของสินค้าชิ้นเดียวกันนี้จะถูกตั้งให้เหมาะเจาะกับ willingness to pay ที่แตกต่างกันไปของลูกค้าทุกคนในตลาด จะกลายเป็นว่าสินค้าชิ้นเดียวกันจะมีราคาที่แตกต่างกัน และจะมีป้ายราคามากมายก่ายกองเท่ากับจำนวนลูกค้าทั้งหมดในตลาดก็เป็นได้ เรียกได้ว่าเป็นการคั้นกำไรออกมาจากกระเป๋าสตางค์พวกเราได้แบบหมดทุกหยดนั่นเอง
FDPD นั้นแต่เดิมเหมือนเป็นเพียง “สัตว์ในเทพนิยาย” สำหรับนักเศรษฐศาสตร์เท่านั้น เนื่องจากมันเป็นไปได้ยากมากที่เราจะสามารถหยั่งรู้ถึง willingness to pay ของผู้บริโภคทุกคน แต่ด้วยความล้นหลามของข้อมูลในปัจจุบันและความนิยมในการซื้อของออนไลน์ FDPD อาจเกิดขึ้นได้เร็วกว่าที่พวกเราคิดก็เป็นได้ งานวิจัยด้านเศรษฐศาสตร์ชิ้นนี้พบว่า หาก Netflix รวมข้อมูลภูมิศาสตร์ประชากร (demographics data) เข้ากับข้อมูลพฤติกรรมการใช้อินเทอร์เน็ตของลูกค้าของตนแล้วใช้กลยุทธ์ FDPD เพื่อคิดราคาที่ต่างกันออกไป จะทำให้กำไรเพิ่มขึ้นมากกว่าการใช้แค่ข้อมูลภูมิศาสตร์ประชากรอย่างรุนแรง
Big Data เพื่อการสัญจรและอนาคตของป้ายโฆษณา
Data to shape the future from Route on Vimeo.
ตัวอย่างของการใช้ Big Data ที่ดูเหมือนมาจากโลกอนาคตที่สุดเห็นจะเป็นการใช้เครื่อง GPS ติดตามตัวผู้คนหลายหมื่นคนในประเทษอังกฤษขององค์กรที่ชื่อว่า Route พวกเขากำลังใช้ข้อมูลเหล่านี้เพื่อศึกษาว่ามนุษย์แบบไหน อายุเท่าไหร่ เพศอะไร อาชีพอะไร ที่จะมีปฏิสัมพันธ์กับสื่อและโฆษณาบนท้องถนนมากที่สุด แบ่งออกได้เป็นตามเวลาและพิกัดบนแผนที่อย่างละเอียดยิบ แถมยังมีการศึกษา eye movement (การเคลื่อนไหวของดวงตา) อีกด้วย
ตัวอย่างของสิ่งที่ Route เริ่มเรียนรู้ คือคนอังกฤษเคลื่อนตัวด้วยความเร็วสูงที่สุดเวลาตีห้าถึงหกโมงเช้าในวันอาทิตย์ และช้าที่สุดเวลาสิบถึงสิบเอ็ดโมงเช้าในวันอังคาร คนอายุ 45-54 ปีและผู้ชายเคลื่อนตัวเร็วกว่า และคนอังกฤษใช้เวลาเดินทางโดยเฉลี่ยอาทิตย์ละ 12.2 ชั่วโมง
จริงอยู่ที่คนเราใช้เวลากับอินเทอร์เน็ตและโทรทัศน์ในบ้านมาก แต่ยังไงเราก็ยังเป็นมนุษย์ที่ต้องเดินทาง ข้อมูลและงานวิจัยของ Route จะมีประโยชน์มหาศาลต่อบริษัทที่ต้องการทราบว่าควรเช่าที่เพื่อการโฆษณาตรงไหนในเมือง และเช่าในช่วงเวลาไหนเพื่อให้เหมาะกับกลุ่มลูกค้าเป้าหมายมากที่สุด ผู้ให้เช่าก็จะได้รับประโยชน์จากข้อมูลนี้เช่นกันเพราะว่าจะได้ตั้งราคาได้เหมาะสมตามปริมาณผู้คนที่ผ่านและระยะเวลาที่คนสนใจมองมาเห็น
สิ่งที่น่าสนใจอีกอย่างคือการใช้ข้อมูลความเร็วและพิกัดจากผู้ใช้แอปพลิเคชันที่ชื่อ Waze ที่เพิ่งถูกซื้อไปโดยยักษ์ใหญ่กูเกิลในราคากว่า 1 พันล้านดอลลาร์สหรัฐ Waze นั้นใช้ข้อมูล GPS บวกกับข้อมูล user-input เพื่อหาเส้นทางที่หลายครั้งดีกว่าเส้นทางที่เครื่อง GPS หรือแอปพลิเคชัน GPS อื่นๆ เสนอ บางครั้ง Waze พาผมไปในเส้นทางที่ประหลาดมาก แต่ถึงที่หมายได้เร็วกว่าปกติเกือบสิบนาที ความสามารถในการแนะนำเส้นทางที่ดีกว่าของ Waze นั้นนอกจากจะลดระยะเวลาในการเดินทางให้กับประชาชนแล้วยังจะก่อให้เกิดรูปแบบของการเดินทางแบบใหม่ในเมืองอีกด้วย ซึ่งหากเอาไปรวมเข้ากับสิ่งที่ Route ทำได้แล้วจะก่อให้เกิดโอกาสในการโฆษณาบนท้องถนนใหม่ๆ ที่น่าตื่นเต้นมาก
Big Data ของข่าวสารและเหตุการณ์ทั่วโลก
เรื่องบางเรื่องที่มีความสำคัญต่อสังคมมนุษย์มากๆ เช่น การค้ามนุษย์ ล่าสัตว์สงวน ค้ายาเสพติด สงคราม ความไม่สงบ การประท้วง มักเป็นเรื่องที่ละเอียดอ่อน ซับซ้อน หรือไม่ก็ลึกลับเกินกว่าที่จะใช้หุ่นยนต์วัดเป็นตัวเลขได้ง่ายๆ เหมือนการวัดยอดขายของสินค้าออนไลน์ จึงเป็นไปได้ว่าที่มันยังเป็นปัญหาอยู่ทุกวันนี้ก็เพราะว่าเราไม่รู้จักมันดีพอ หรือไม่ก็รู้จักแต่เฉพาะด้านที่สังเกตเห็นได้
โชคยังดีที่โลกเรามีทีมงานอัจฉริยะของ The GDELT Project ที่ทำการจัดการคลังข้อมูลเกี่ยวกับสังคมมนุษย์ที่ใหญ่ที่สุดในโลกผ่านการเก็บเกี่ยวแล้วใช้สมองกลวิเคราะห์ข่าวสารทุกประเภท เกือบทุกภาษา ตั้งแต่ปี ค.ศ. 1979 มาจนถึงวันนี้ตอนนี้ในทุกพื้นที่บนโลกนี้ (รวมแล้วกว่า 250 ล้านเรื่อง) นอกจากนั้นยังสร้างเน็ตเวิร์กขนาดยักษ์ที่ใช้เรื่องราวเหล่านี้เพื่อเชื่อมโยงบุคคล ประเทศ องค์กร ไปจนถึงอารมณ์ของเรื่องราวเข้าด้วยกันเพื่อการศึกษาต่อไป
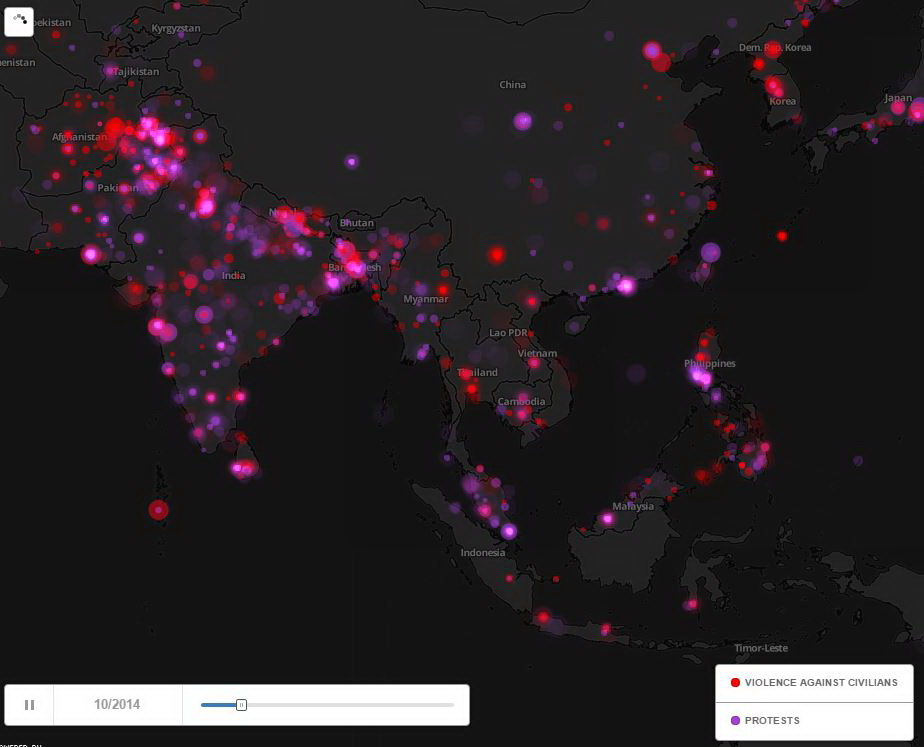
สิ่งที่ตามมาหลังจากที่มีคลังข้อมูลนี้นั้นน่าสนใจมาก ยกตัวอย่างเช่น Global Conflict Dashboard ที่แสดงตำแหน่งและความถี่ของความไม่สงบทั่วโลก ไปจนถึงการศึกษาข้อมูลเพื่อแก้ปัญหาเด็กถูกลักพาตัวในประเทศไนจีเรียโดยการใช้สมองกลทำนายล่วงหน้าว่าจะเกิดการลักพาตัวเด็กหญิงในประเทศไนจีเรียอีกครั้งเมื่อไหร่ที่ไหน
อีกตัวอย่างสำคัญด้านบนคือแผนที่โลกที่แสดงให้เห็นถึงความถี่ของข่าวเรื่องการล่าสัตว์ที่ผิดกฎหมาย เช่น การล่างาช้าง หรือการประมงเถื่อน แม้ว่ายังมีอีกหลายสิ่งที่แผนที่นี้ตอบไม่ได้ แต่สิ่งหนึ่งที่เห็นได้ชัดคือการล่าสัตว์แบบผิดกฎหมายนั้นเป็นอะไรที่เกิดขึ้นแทบจะทุกหนทุกแห่งบนโลก ไม่ใช่แค่ในทวีปแอฟริกาหรือในประเทศใดประเทศหนึ่งเท่านั้น
จริงอยู่ที่ความรู้ความเข้าใจที่ออกมาจากการใช้ Big Data ในรูปแบบของ the GDELT Project จะยังอยู่แค่ในระยะเริ่มต้น แต่มันจะเป็นก้าวสำคัญในการค้นหาวิธีแก้ปัญหาใหญ่ๆ ที่ทั้งลึกลับทั้งนานาชาติในสังคมมนุษย์ในอนาคตอย่างแน่นอน
สัมผัสกับโลกของ Open Data
ที่ผมใช้คำว่า “สัมผัส” แทนคำว่า “มาฟังเรื่องราว” หรือ “มาทำความรู้จักกับ” ก็เพราะว่า Open Data มันเป็นอะไรที่คุณต้องสัมผัสเองถึงจะเข้าใจถึงความยิ่งใหญ่และความเป็นไปได้อันไร้ขีดจำกัดของมัน
คงต้องยอมรับว่าหลายตัวอย่างด้านบนเป็นตัวอย่างของ Big Data ที่ไม่เปิดเผยต่อประชากรทั่วไป หรือถ้าเปิดเผยก็เข้าถึงและเอาไปใช้ต่อได้อย่างยากลำบากมาก เมื่อไม่กี่ปีที่ผ่านมานี้ได้เริ่มมีความเคลื่อนไหวใหม่ที่เรียกว่า Open Data ซึ่งมีหลายความหมาย ผมขออนุญาตนิยามมันในที่นี้ว่า:
Open Data คือไอเดียที่ว่าประชาชนต้องสามารถเข้าถึงข้อมูลสาธารณะ (ไม่ว่ามันจะมีขนาดใหญ่แค่ไหน) ได้อย่างไร้อุปสรรคที่สุดเท่าที่จะทำได้
เพื่อให้ผู้อ่านเข้าใจถึงความสำคัญของ Open Data และเพื่อให้ผู้อ่านเห็นภาพมากที่สุด ต่อไปนี้คือสิ่งที่ประชากรที่อยู่อาศัยในบางเมืองในประเทศสหรัฐอเมริกาสามารถทราบได้เพียงแค่ไม่กี่คลิก:
1. รถแท็กซี่คันไหนจอดรับส่งผู้โดยสารที่ไหน ใช้เส้นทางไหน ได้เงินเท่าไหร่ ได้ทิปเท่าไหร่บ้าง ทุกวัน ทุกวินาที ตั้งแต่ปี 2009 (ลองดู visualization เรื่องราวของแท็กซี่แต่ละคันในเมืองนิวยอร์กในปี 2013 ได้ที่นี่)
2. ภาษีที่ดินที่เจ้าของตึกทุกตึกในเมืองคุณเสียให้กับรัฐบาลไปเมื่อปีที่แล้ว จะเอาตึกไหนก็เลือกดูได้เลย
3. รอบๆ ตัวคุณมีต้นไม้กี่ต้น รัฐบาลเอามาปลูกไว้ตั้งแต่เมื่อไหร่
4. ในย่านที่คุณอยู่อาศัยมีอัตราการก่ออาชญากรรมสูงแค่ไหนเทียบกับย่านที่คุณกำลังจะตัดสินใจซื้อบ้านใหม่
5. บริษัทไหนในเมืองคุณที่ทำธุรกรรมกับองกรค์ภาครัฐมากที่สุด ซื้อขายอะไรมากที่สุด ดูได้เป็นจำนวนเม็ดเงินในแต่ละเชคเลยทีเดียว
6. ร้านอาหารโปรดชื่อดังในตรอกที่พ่อคุณชอบไปรับประทาน มีความสะอาดเลิศหรูเหมือนกับรสชาติของอาหารหรือไม่ ในการสุ่มตรวจครั้งที่แล้วมีหนูในครัวบ้างไหม
7. เทศบาลของคุณสามารถซ่อมถนน ซ่อมไฟถนน หรือย้ายสิ่งกีดขวางที่เป็นอันตรายบนท้องถนนได้เร็วแค่ไหนหลังจากที่คุณโทรศัพท์ไปแจ้ง เทศบาลของคุณมีประสิทธิภาพขึ้นบ้างไหมในช่วงห้าปีที่ผ่านมาหรือว่าแย่ลงเรื่อยๆ
8. เจ้าหน้าที่ฉุกเฉินในเมืองคุณมีศักยภาพแค่ไหน
9. ตำแหน่งราชการในเมืองที่ มีเงินเดือนมากสุด (เสร็จแล้วก็ไปหาต่อเองว่าชื่ออะไร!)
นี่เป็นเพียงตัวอย่างไม่กี่ตัวอย่างที่ Open Data สามารถทำให้ประชากรสามารถเข้าใจสิ่งที่เกิดขึ้นรอบตัวเองได้อย่างรวดเร็ว ละเอียด และเที่ยงตรง ซึ่งในหลายเรื่องดีกว่าการพึ่งพิงข้อมูลจากหนังสือพิมพ์ ลมปากของนักการเมือง หรือการเล่าสู่กันฟังในกลุ่มเพื่อน
การเข้าถึง Open Data นั้นมีหลากหลายวิธีมากมาย บางเมืองใหญ่ๆ จะมีเว็บไซต์สำหรับ Open Data โดยเฉพาะ เช่น นิวยอร์ก เป็นต้น เว็บไซต์สังกัด data.gov เหล่านี้ใช้งานง่าย ดาวน์โหลดข้อมูลง่าย แถมยังสามารถพล็อตข้อมูลดูได้เลยโดยไม่ต้องดาวน์โหลดให้เสียเวลาอีกด้วย

ผู้อ่านท่านใดเคยเล่นเกมสร้างเมือง Sim City ขอให้ลองเข้าไปดูโปรเจกต์ Corridorscope: Water Street ที่เอาข้อมูลเหล่านี้ไปทำ data visualization ในแบบที่ว่าเห็นทุกพฤติกรรมมนุษย์ในพื้นที่ที่มีคนเดินผ่านมากที่สุดพื้นที่หนึ่งในเมืองนิวยอร์ก ทุกๆ วินาทีที่ผ่านไปเราจะสามารถเห็นได้ว่ามีคนใช้ wifi แค่ไหน มีขยะถูกทิ้งลงในถังขยะ smart แค่ไหน มีการโทรศัพท์แจ้ง non-emergency service แค่ไหนในทุกๆ จุดในพื้นที่ดังกล่าว อีกไม่นานการเป็นผู้ว่าราชการจังหวัดอาจมีส่วนคล้ายการสร้างและดูแลเมืองด้วยความแม่นยำอย่างใน Sim City ก็เป็นได้!

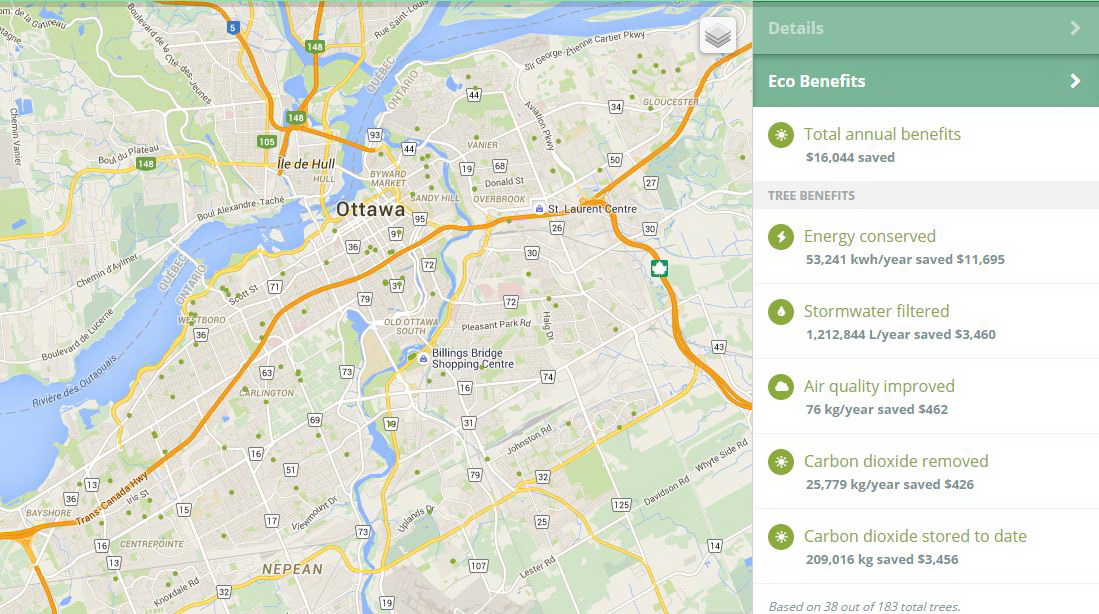
แต่ที่ผมประทับใจที่สุดเห็นจะเป็นเว็บไซต์ชื่อ Plenario ที่ทำการเชื่อมโยงข้อมูล Open Data จำนวนมหาศาลจากหลายๆ เมือง หลายๆ มลรัฐเข้าด้วยกัน ทำให้การค้นหาข้อมูลง่ายยิ่งกว่าเดิม เพียงคุณลากเส้นวาดขอบเขตที่คุณสนใจในแผนที่ ระบุวันเวลาหัวท้าย Plenario จะทำการแสดงข้อมูลทั้งหมดที่อยู่ในคลังข้อมูลจากหลายๆ เว็บไซต์ให้เพียงไม่กี่วินาทีดังภาพข้างบน
การออกแบบเว็บไซต์เหล่านี้นั้นเป็นตัวอย่างที่ดีสำหรับทางการไทยในอนาคต เพราะผู้ดีไซน์มีจุดมุ่งหมายเพื่อที่จะทำให้ผู้ใช้งานสามารถเข้าถึงข้อมูลได้อย่างง่ายดายและรวดเร็วที่สุด คลิกไม่เกิน 5 ครั้งจะต้องเข้าถึงข้อมูลได้ และในบางกรณีเข้าถึงได้แบบลึกมากๆ ด้วย สามารถเลือกประเภทของไฟล์ได้ตามซอฟต์แวร์ที่เราถนัด นั่นเป็นเพราะว่าคนที่ออกแบบและรัฐบาลเขาเข้าใจในความหมายและเชื่อในจุดมุ่งหมายของ Open Data อย่างแท้จริง ว่าการเปิดเผยข้อมูลตามกฎหมายแค่นั้นไม่พอ มันช้า ต้องเปิดเผยและทำให้เข้าถึงได้อย่างไร้อุปสรรคด้วย
เขาไม่ใช่ทำไปเพียงเพราะว่ากฎหมายหรือประชาชนบังคับให้ทำ แต่สำคัญคือต้องมีความเชื่อมั่นในอุดมการณ์ว่า Open Data จะพาสังคมไปในจุดที่สูงกว่า
ประโยชน์อันมหาศาลของ Open Data
นอกจากที่ Open Data จะเป็นการกระจายความรู้ “รอบตัว” เกี่ยวกับชุมชนให้กับประชาชนแล้ว Open Data ยังมีประโยชน์อีกมากในระดับที่สังคม เช่น การพัฒนานโยบายสาธารณะ (Public Policy) เพิ่มปริมาณและคุณภาพของความเป็นพลเมืองที่ดี พัฒนาความสามารถและประสิทธิภาพของภาครัฐ และเพิ่มความรู้ความเข้าใจในด้านสังคมศาสตร์ “อย่างเป็นวิทยาศาสตร์” มากขึ้นเกี่ยวกับพฤติกรรมมนุษย์และสิ่งต่างๆ ที่เรามองไม่เห็นหรือมองได้ไม่ครบด้วยตาเปล่า

ข้อมูลรถแท็กซี่กับข้อมูลความสะอาดของร้านอาหารอาจจะฟังดูเป็นเรื่องเล็กน้อยในการบริหารบ้านเมือง แต่หากลองนึกดูว่าถ้าสามารถเชื่อมโยงข้อมูลแท็กซี่เข้ากับข้อมูลสภาวะอากาศ ข้อมูลรถประจำทาง ข้อมูลรถไฟไต้ดิน ข้อมูลการเดินทางจาก Route และ Waze จะเกิดการจุดประกายขนาดไหน และในอีกไม่กี่ปีเราก็อาจจะตอบคำถามได้เสียทีว่ามี Uber ดีสำหรับสังคมกว่าไม่มี Uber หรือไม่ มี Uber แล้วทำให้การจราจรหนาแน่นกว่าปกติจริงๆ หรือไม่ แท็กซี่มีรายได้วันละเท่าไหร่ สมควรปกป้องไม่ให้มีคู่แข่งหรือไม่ มี Uber แล้วประชาชนที่อาศัยอยู่ชานเมืองที่ไม่มีรถโดยสารไปถึงสามารถเข้ามาทำงานในเมืองเร็วขึ้นหรือไม่ คำถามเหล่านี้ไม่มีทางตอบได้เลยหากไม่มีข้อมูลอันมหาศาล นอกจากนั้น ข้อมูลเหล่านี้ยังสามารถทำให้เราเข้าใจพฤติกรรมมนุษย์ในเชิงทฤษฎีได้ดีขึ้นอีกด้วย ยกตัวอย่างเช่น มี งานวิจัยทางเศรษฐศาสตร์งานหนึ่งที่ใช้ข้อมูลแท็กซี่กับข้อมูลสภาพอากาศเพื่อทำให้เราเข้าใจการตัดสินใจในการ “ทำงานหาเงิน” แลกกับการ “ไม่ขับเพื่อพักผ่อน” ในหมู่คนขับแท็กซี่ในวันที่ฝนตกและฝนไม่ตก เป็นต้น
ส่วนข้อมูลความสะอาดของร้านอาหารนั้น หากนำไปวิเคราะห์ร่วมกับข้อมูลรายได้ของร้านอาหารที่ต้องรายงานเพื่อการชำระภาษีอย่างในงานวิจัยนี้จะทำให้ภาครัฐทราบได้ว่าป้ายคำเตือนความสะอาดที่แปะอยู่ที่ประตูทางเข้าของทุกร้านนั้นมีผลหรือไม่ ผู้บริโภคเปลี่ยนใจหันไปรับประทานอาหารจากร้านที่มีป้าย “สะอาดดีมาก” มากขึ้นหรือไม่หลังจากที่ภาครัฐทำการแปะป้ายประกาศ หากไม่มีผลจะได้พยายามหาวิธีอื่นเพื่อให้ผู้บริโภคทราบ เช่น ทำป้ายให้มองเห็นง่ายขึ้น หรือบังคับให้ร้านอาหารบอกข้อมูลนี้กับผู้บริโภคด้วยวิธีอื่น ในอนาคตจะต้องมีการนำข้อมูลนี้ไปรวมกับข้อมูลสาธารณสุขเพื่อวิเคราะห์ถึงผลกระทบของความสะอาดของอาหารต่ออัตราป่วยด้วยโรคต่างๆ ที่เกี่ยวข้องอย่างแน่นอน
รัฐบาลได้อะไรจาก Open Data
ก่อนที่บทความยาวๆ บทนี้จะจบ ยังมีอีกหนึ่งคำถามสำคัญ นั่นก็คือ แล้วรัฐบาลได้อะไร?
Open Data นั้น สำหรับรัฐบาลแล้ว หลายคนคิดว่าไม่น่ามีเหตุผลที่รัฐบาลจะต้องการเพิ่มงานและความเหน็ดเหนื่อยให้กับตัวเอง แต่ผมคิดว่า Open Data สามารถเป็น win-win situation ได้ในระยะยาว โดยเฉพาะอย่างยิ่งสำหรับรัฐบาลที่มีความรับผิดชอบ ต้องการให้ประสิทธิภาพของตนเองเพิ่มขึ้น และต้องการแสดงความโปร่งใสในการทำงานอย่างแฟร์ๆ ให้กับสังคมที่มี accountability สูง (ซึ่งผมเองยังไม่แน่ใจว่าสังคมไทยมาถึงจุดนั้นแล้วหรือยัง)
โลกใบนี้คงไม่มีสังคมไหนที่ประชาชนไม่ต้องการความเป็นอยู่และบริการทางสาธารณสุขที่ดีขึ้น หากรัฐบาลใดพิสูจน์ได้อย่างโปร่งใส ว่าความสำเร็จของตนมีที่มาที่ไป ว่ารัฐบาลใส่ใจในความเป็นอยู่ของประชาชน ว่าตื่นตัวและรู้ทันปัญหาสังคม ว่าไม่มีการโกงกินจริงๆ ว่าเงินเดือนข้าราชการเหมาะสมกับประโยชน์ต่อสังคมที่มาจากหยาดเหงื่อของข้าราชการผู้นั้น ทั้งหมดนี้ก็จะสร้างความนิยมอย่างไม่หลอกลวงในหมู่ประชาชนได้มากเป็นธรรมดา ที่สำคัญที่สุดคือเป็นการสร้าง “ความเชื่อใจ” ระหว่างภาคประชาชนกับภาครัฐที่ทุกวันนี้น้อยลงทุกทีในบ้านเรา
ความเชื่อมั่นในอุดมการณ์นี้ของผู้นำแล้ว ส่วนหนึ่งก็เป็นเพราะบทบาทของกฎหมายที่ชื่อว่า Freedom of Information Act ที่ให้อำนาจกับประชาชนในการสอบถามข้อมูลจากรัฐบาล การสอบถามนั้นง่ายดายเพียงแค่กรอกฟอร์มหรือส่งอีเมลไปขอแค่นั้น อีกไม่กี่วันก็เอาฮาร์ดดิสก์ไปรับไฟล์ และที่ความเคลื่อนไหวนี้กำลังไปได้ดีอย่างมี momentum ก็เป็นเพราะว่ามีคนทำ platform เว็บไซต์รวบรวมข้อมูลที่ออกมาจากการใช้สิทธินี้ที่ผมได้เกริ่นไปแล้ว อีกหน่อยข้อมูลสาธารณะก็จะถูกบรรจุในเว็บไซต์เหล่านี้และได้รับการอัปเดตจนข้าราชการไม่ต้องเหนื่อยนั่งตอบอีเมลคนที่จะมาขอข้อมูลทีละอีเมล เผลอๆ รัฐบาลจะประหยัดเงินค่าจ้างในส่วนนี้ได้อีกด้วยเพราะว่าระบบมันทำของมันเอง
นี่มัน win-win situation ชัดๆ จริงๆ
อนาคตของ Open Data ขึ้นอยู่กับพวกเราเอง

ข้อมูลสาธารณะอันมหาศาลที่มาพร้อมกับปรากฏการณ์ Big Data จะเป็นแค่ตัวเลข 0 1 และจะเป็นขยะในฮาร์ดดิสก์ที่ไร้ประโยชน์หากมันถูกซ่อนอยู่ในมุมมืดหรืออยู่ในมือของกลุ่มคนแค่ไม่กี่คน
ชะตากรรมของ Open Data ในแต่ละท้องที่จะขึ้นอยู่กับคนสองกลุ่มใหญ่ นั่นก็คือ ประชาชนและรัฐบาล เพราะว่าหากเราลองดูกรณีของประเทศอื่นๆ ความสำเร็จของ Open Data นั้นจะต้องมีความร่วมมือของสองฝ่ายเสมอ ไม่ใช่ฝ่ายใดฝ่ายหนึ่งทำแต่อีกฝ่ายไม่ตอบสนอง
และที่สำคัญที่สุดก็คือ ไม่ใช่แค่วิศวกรคอมพิวเตอร์ นักสถิติ หรือนักเศรษฐศาสตร์เท่านั้นที่จะสามารถใช้ประโยชน์จากข้อมูลสาธารณะเหล่านี้
จุดนี้เป็นจุดเริ่มต้นที่ทุกคนควรเข้าใจ ว่าเราไม่มีทางทราบได้หรอกว่าข้อมูลเหมาะกับใครและเขาจะเอาไปทำอะไรได้ การปิดกั้นโอกาสนั้นเท่ากับว่าเป็นการปิดโอกาสของสังคมที่เต็มไปด้วยผู้คนที่มากด้วยความสามารถและประสบการณ์ที่หลากหลาย
เราทุกคนสามารถรับและสร้างประโยชน์จาก Open Data นี้ได้ในรูปแบบของเราเอง ตั้งแต่ในรูปแบบที่เล็กที่สุดที่ทุกคนทำได้ซึ่งก็คือการทำตัวเป็นประชาชนที่มีคุณภาพขึ้นเพราะว่าตน “รับรู้” ว่ามีอะไรเกิดขึ้นรอบๆ ไปจนถึงในรูปแบบของการดึง Correlative Insights จากข้อมูลเหล่านี้ด้วยความรวดเร็วจากสมองกล แบบ Machine Learning หรือแม้กระทั่งไปจนถึงรูปแบบของการดึง Causality (อะไรเป็นเหตุเป็นผล) จากข้อมูลเหล่านี้โดยใช้สมองคนที่พึ่งทฤษฎีทางสถิติพร้อมกับสมองกล
ผมเองในฐานะประชาชนคนหนึ่งและนักวิจัยด้านเศรษฐศาสตร์ก็กำลังทำหน้าที่เสนอแนวคิดนี้ผ่านบทความบทนี้และจะทำการดึง Causality ออกมาแสดงในงานวิจัยของผมในอนาคตให้กับเพื่อนร่วมสังคมเพื่อที่จะชี้ให้เห็นถึง “โอกาส” ในการผลักดันสังคมให้ก้าวไปข้างหน้าในหลายๆ มิติ
เมื่อรัฐบาลทำการเปิดเผยข้อมูล ข้อมูลสาธารณะเหล่านี้จะถูกนำไปใช้และวิเคราะห์โดยประชาชนทุกอาชีพ ทุกวัย ทุกหนทุกแห่ง บางเมืองเขาจัดการแข่งขันตั้งเงินรางวัลสำหรับทีมที่สร้างแอปพลิเคชันที่มีประโยชน์ต่อสังคมที่สุด ผลออกมาก็คือมีแอปพลิเคชันอย่างล้นหลามให้ประชาชนได้เลือกใช้ได้ตามสะดวก
มนุษย์ที่มีความคิดดี มีทักษะดี และมีจิตใจดีงาม ก็จะนำข้อมูลเหล่านี้ไปก่อให้เกิดประโยชน์ต่อสังคม ผลักดันสังคมไปข้างหน้า ไม่ว่าจะเป็นในด้านความปลอดภัย การศึกษา หรือสิ่งแวดล้อม แทนที่คนเหล่านี้จะอดใช้ความสามารถและความหวังดีที่ตนเองมีแบบในสมัยก่อนที่ข้อมูลเหล่านี้ถูกเก็บซ่อนไว้
ทั้งหมดนี่ฟังดูเหมือนฝัน แต่ถ้าไม่ร่วมกันฝันและเชื่อมั่นในฝันตั้งแต่วันนี้และไม่จินตนาการสิ่งที่กำลังจะเป็นไปได้…
ฝันก็คงไม่เป็นจริง
หมายเหตุ: ตีพิมพ์ครั้งแรกที่ “เศรษฐ” ความคิด – settaKid.com ณ วันที่ 14 กันยายน 2558
ข่าวหรือบทความที่เกี่ยวข้อง





