จรัล งามวิโรจน์เจริญ

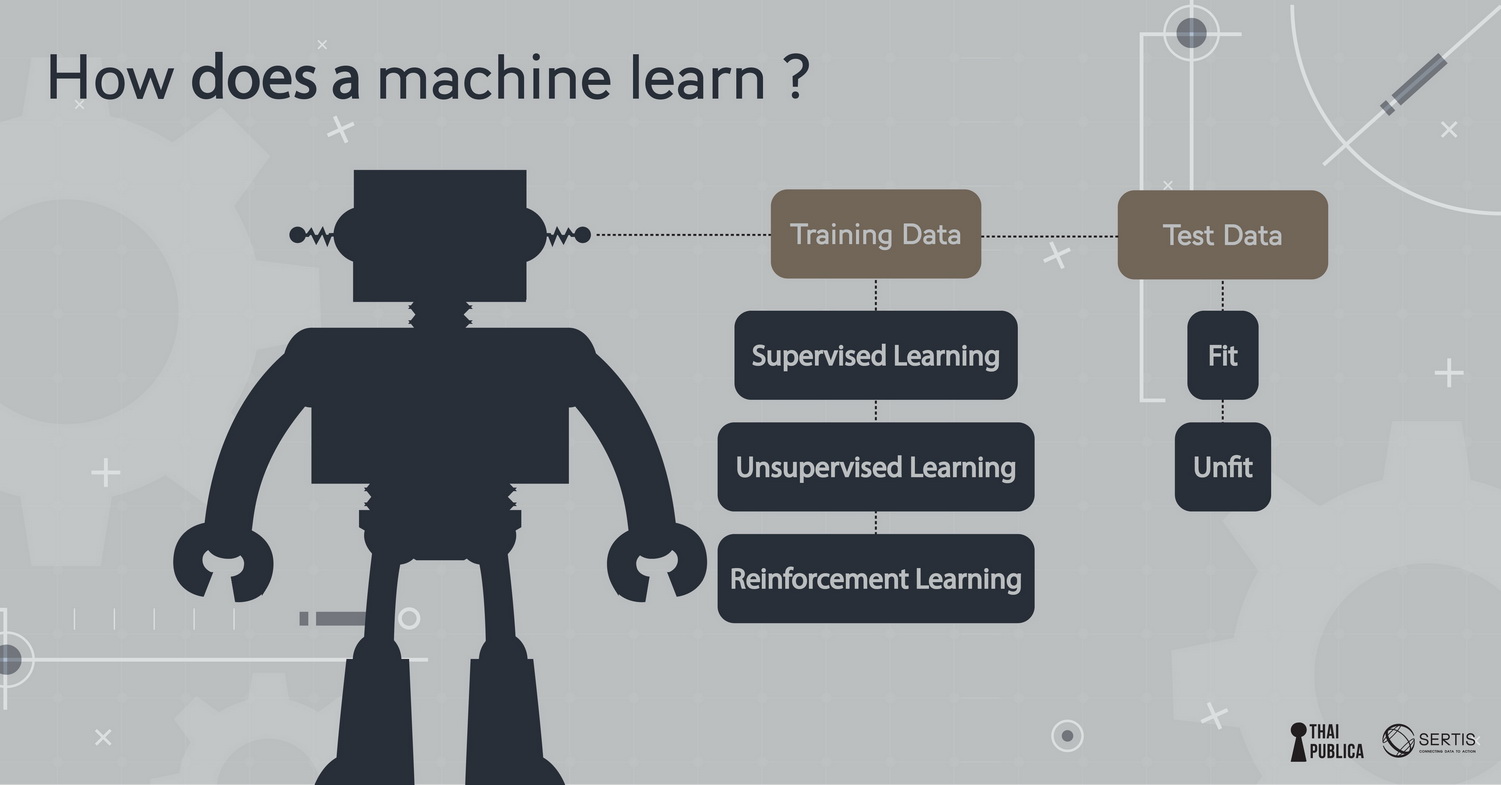
คราวที่แล้วผมได้พูดถึงพื้นฐานการเรียนรู้ทั่วไปของคน คราวนี้เรามาดูว่าคอมพิวเตอร์มีวิธีการเรียนรู้อย่างไรบ้าง Machine Learning (เรียกย่อๆ ว่า ML) เป็นศาสตร์แขนงหนึ่งของ Artificial Intelligence โดยใช้ concept ที่คล้ายการเรียนรู้ของคนมาสอนคอมพิวเตอร์ ML เรียนรู้จากการสังเกต data ด้วยการสอนเครื่องให้เรียนรู้ data ด้วยวิธีต่างๆ เรียกว่า training data ซึ่งเอาไว้สอนเครื่องด้วย model แบบต่างๆ จากนั้นจึงนำโมเดลที่ถูกสอนเหล่านั้นมาทดสอบกับชุดข้อมูลอื่นๆ ว่า model fit กับ data หรือไม่ ถ้า model ทำนายตอน training ได้ดีใกล้เคียงกับ testing ก็แสดงว่า model fit กับ data ซึ่งผมจะอธิบายในรายละเอียดต่อไป
ภาพที่ 1: การเรียนรู้ของเครื่องอย่างง่าย

การสอนเครื่องให้สร้างโมเดลมีดังนี้
1.การ Training data คือ การสังเกตปรากฎการณ์โลกโดยใช้ตัวอย่างของ data ในอดีตหรือปัจจุบัน
2.สร้าง model ที่เข้ากับปรากฎการณ์โลกโดยปรับแต่งต้วแปร(parameter) ต่างๆ ของ model ซึ่งลักษณะของ model หลักๆ มี 3 แบบ คือ supervised learning, unsupervised learning, และ reinforcement learning จากนั้นจึงทดสอบว่า data fit กับโมเดลหรือไม่
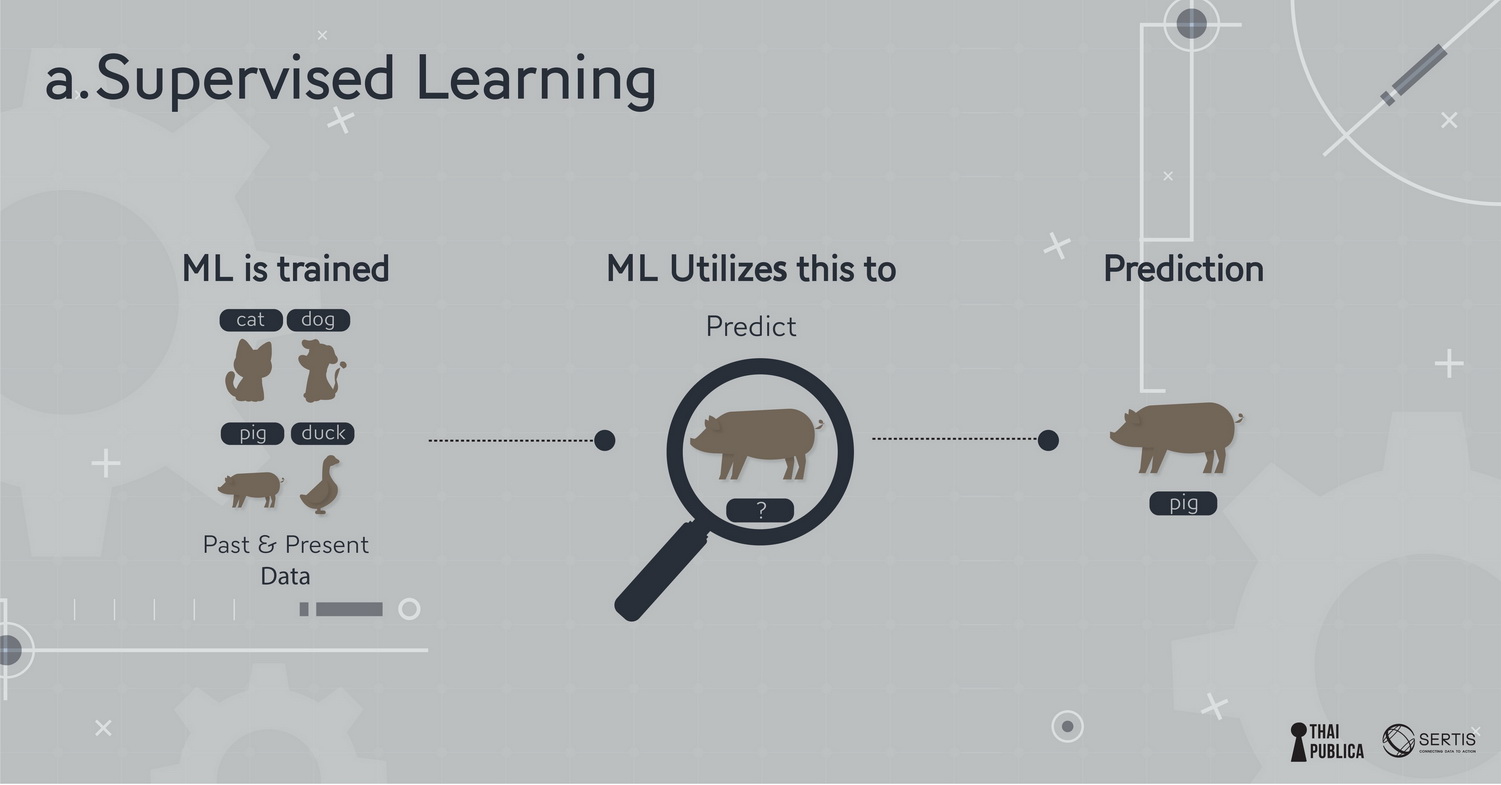
ภาพที่ 2: โมเดลที่ถูกสอนแบบ supervised learning
a.ถ้า model ถูกสอนให้สังเกตข้อมูลอดีตหรือปัจจุบันเพื่อตอบคำถามให้ตรงตามเฉลย (ทาง ML เรียกเฉลยว่า label) แล้วนำมาใช้ในการคาดการณ์หรือทำนาย (prediction) คำตอบบน data ชุดใหม่ (ที่เรียกว่า test data) เหมือนติวหนังสือสอบจากตัวอย่าง (training) แล้วไปสอบจริง (testing) เราเรียกว่า supervised learning เช่น ผมอาจจะมีข้อมูลของคุณสมบัติของพนักงาน (GPA, คะแนนสอบเชิงพฤติกรรม, ระดับการศึกษา, ประสบการณ์การทำงาน, กิจกรรม, งานอดิเรก) ที่บริษัทรับเข้ามากับประสิทธิภาพในการทำงาน (ดีเยี่ยมเป็นซุปตาร์, เฉยๆ, แย่) แล้วมาสอน model ให้ทำนายว่าถ้ามี candidate ใหม่เค้าน่าจะเป็นคนที่มีประสิทธิภาพในการทำงานไหม

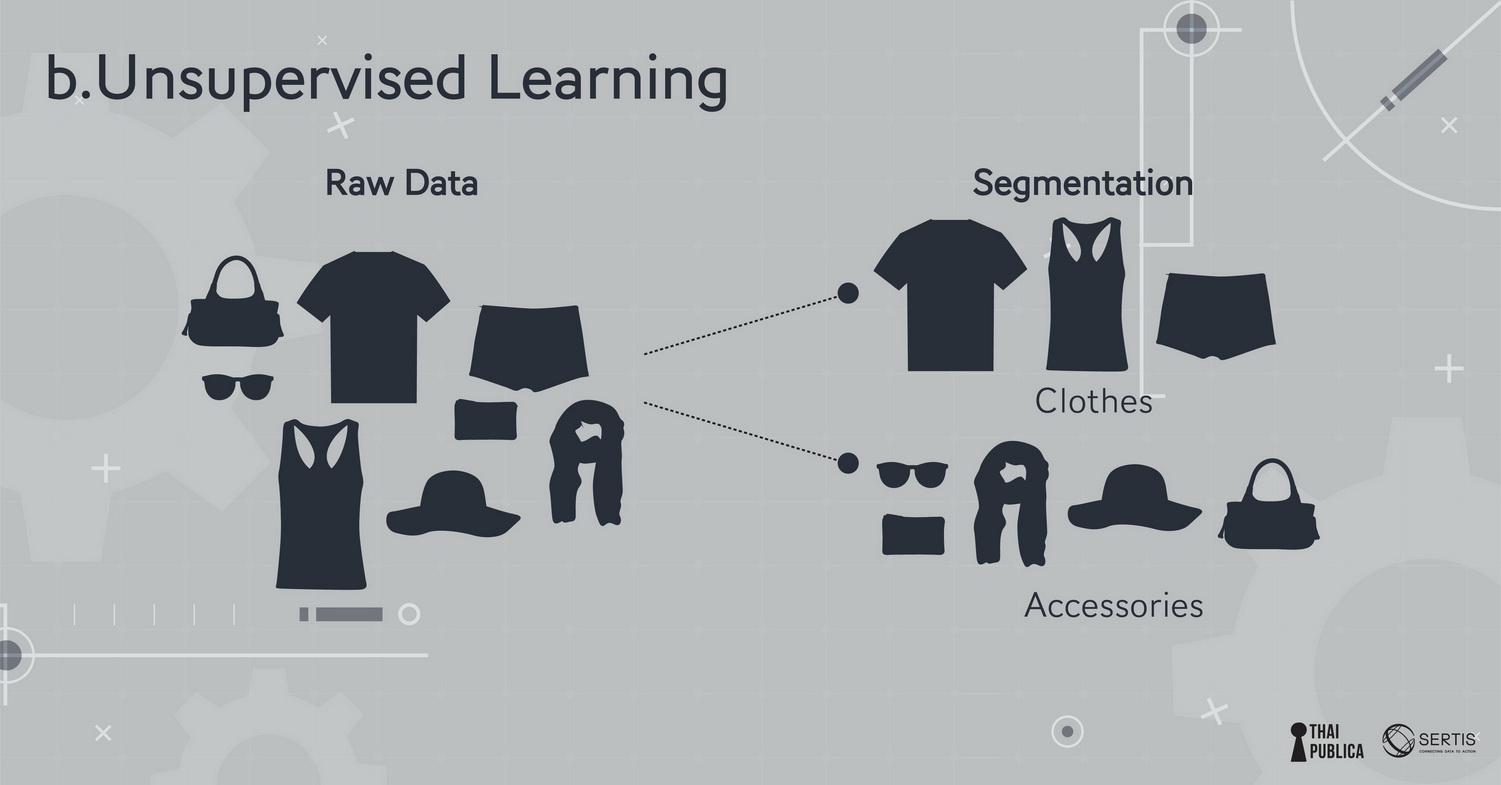
ภาพที่ 3: โมเดลที่ถูกสอนแบบ unsupervised learning
b.ถ้าเป็น model ที่ให้แยกหมวดหมู่หรือจัดกลุ่ม (segmentation/ clustering) โดยไม่จำเป็นต้องใช้เฉลย (label) มาเป็นตัวสอน เราเรียกว่า unsupervised learning เช่น บริษัทมีสินค้าเสื้อผ้าสตรีที่ลักษณะต่างๆ กัน (สี, เนื้อผ้า, style, ประเภทการใช้) ก็สามารถใช้ข้อมูลการซื้อขายของลูกค้ามา train ให้ model แยกแยะความชอบ (preference) ของกลุ่มได้
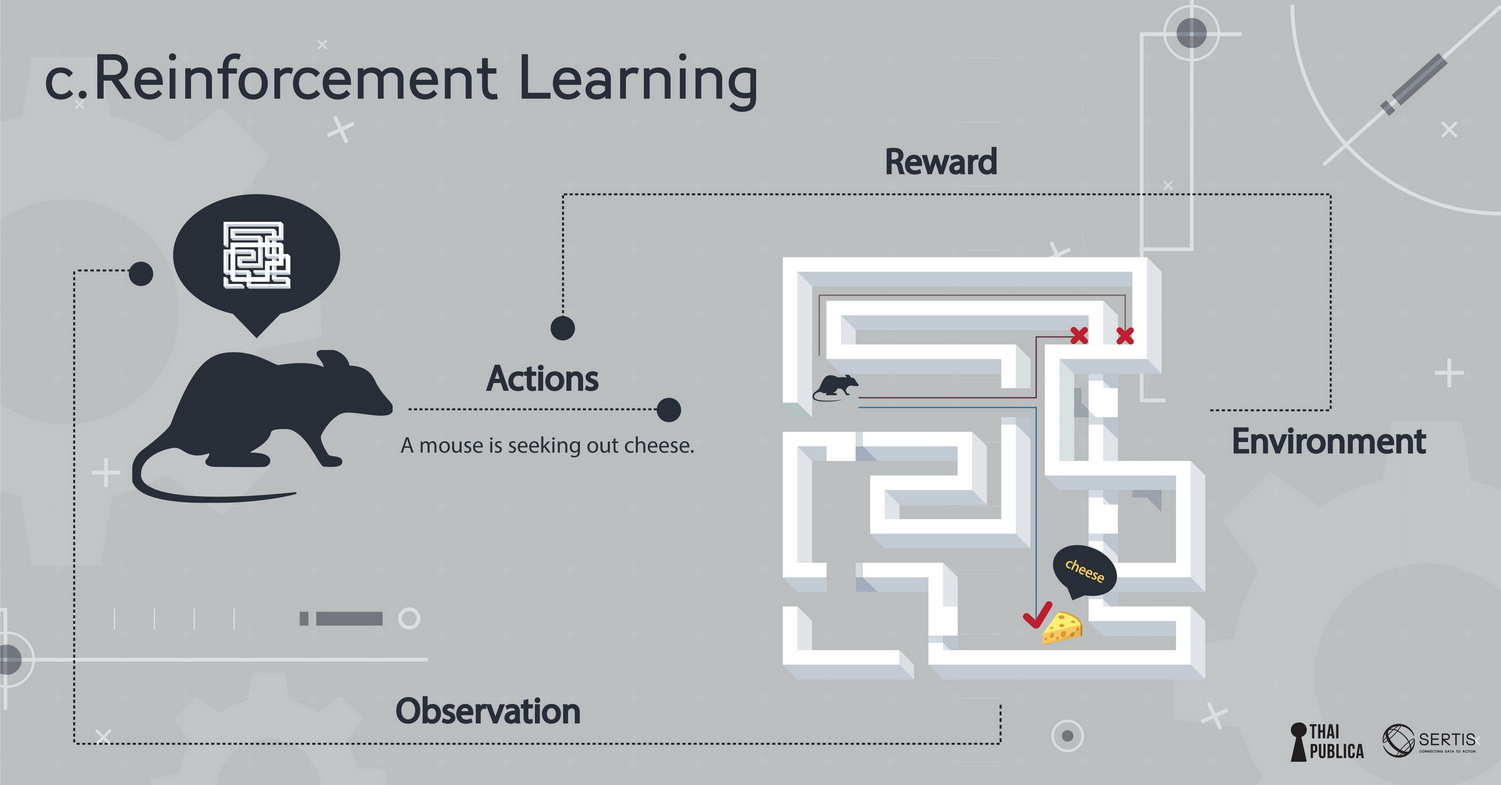
ภาพที่ 4: โมเดลที่ถูกสอนแบบ reinforcement learning

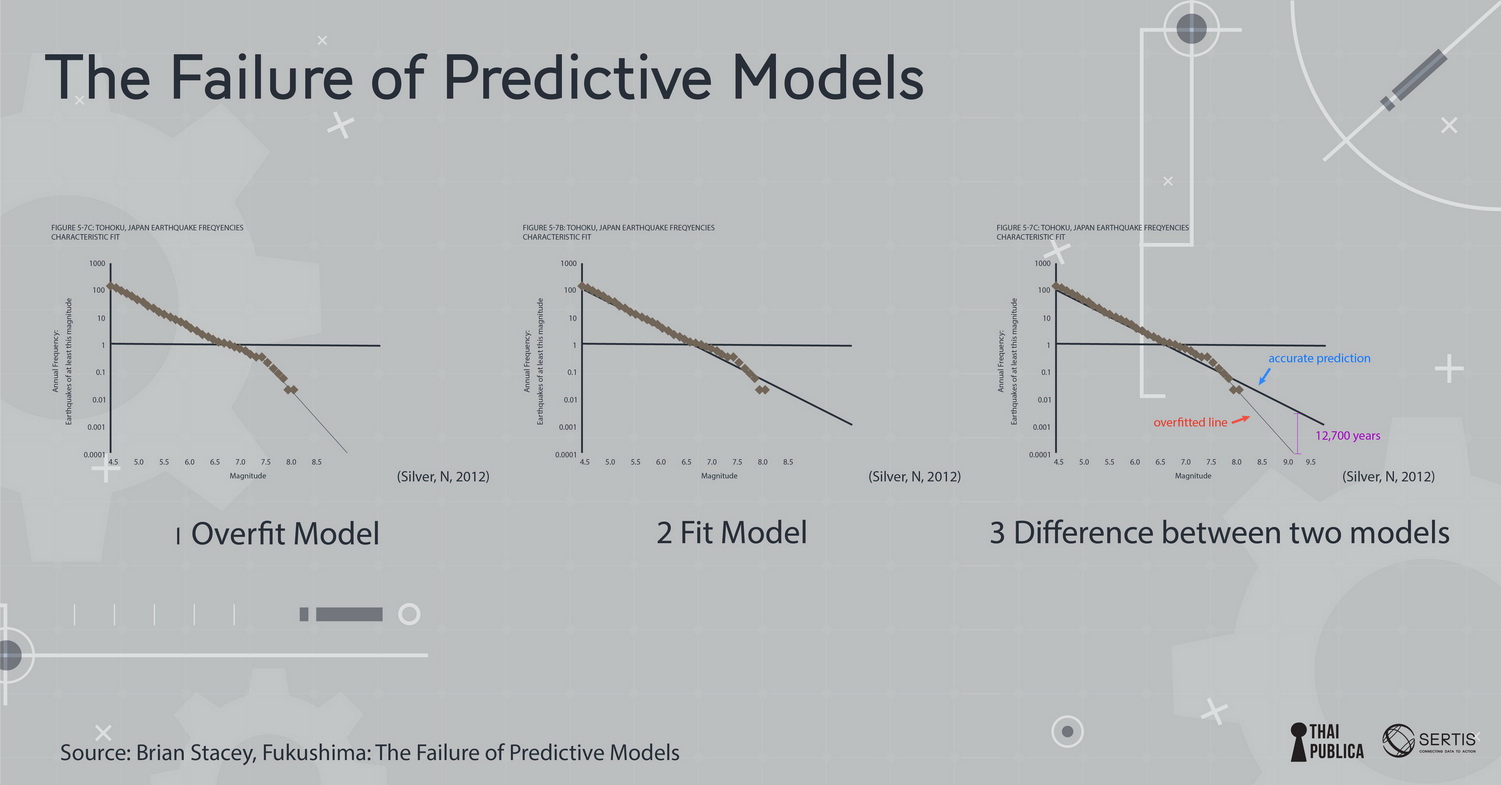
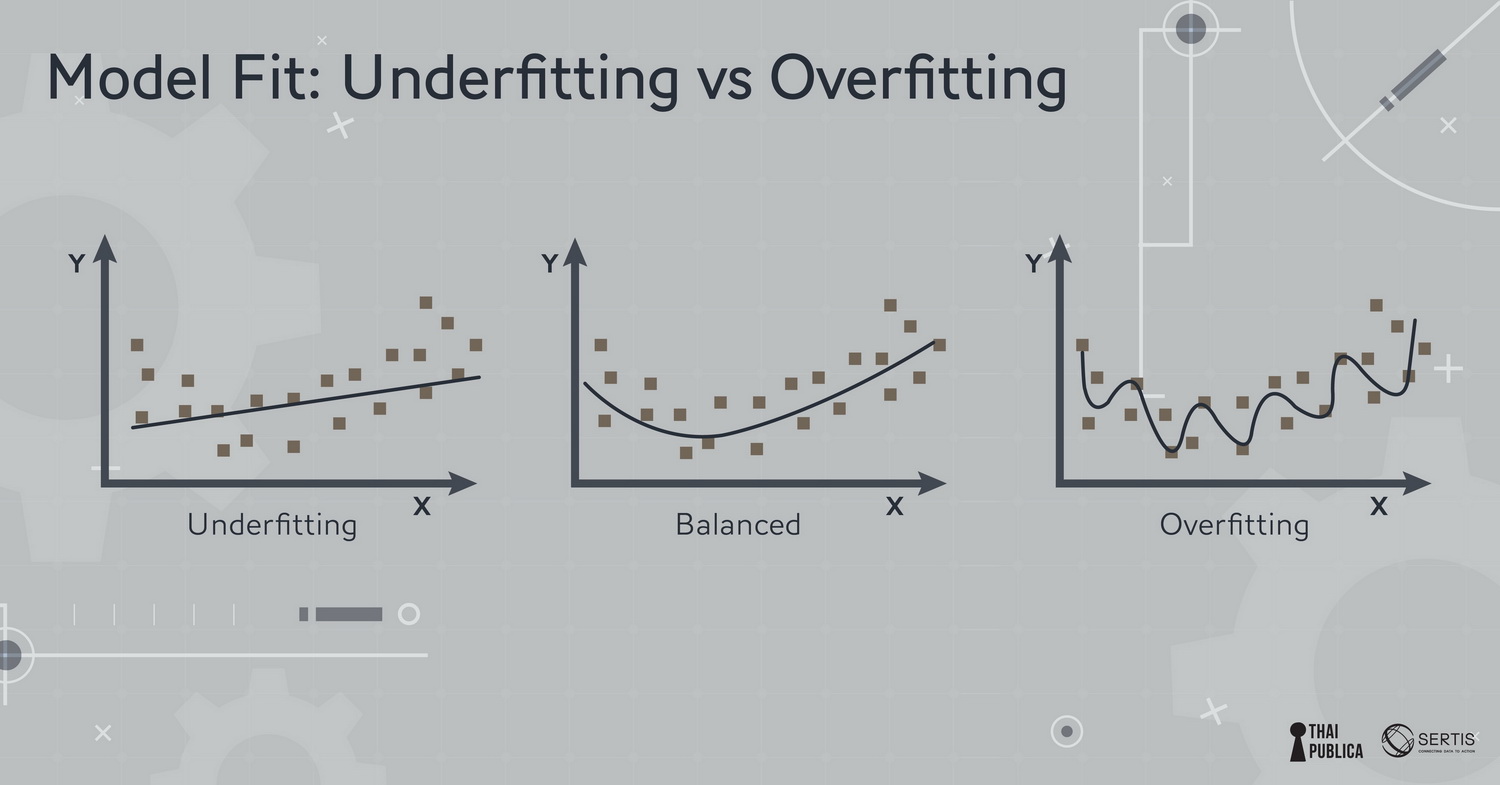
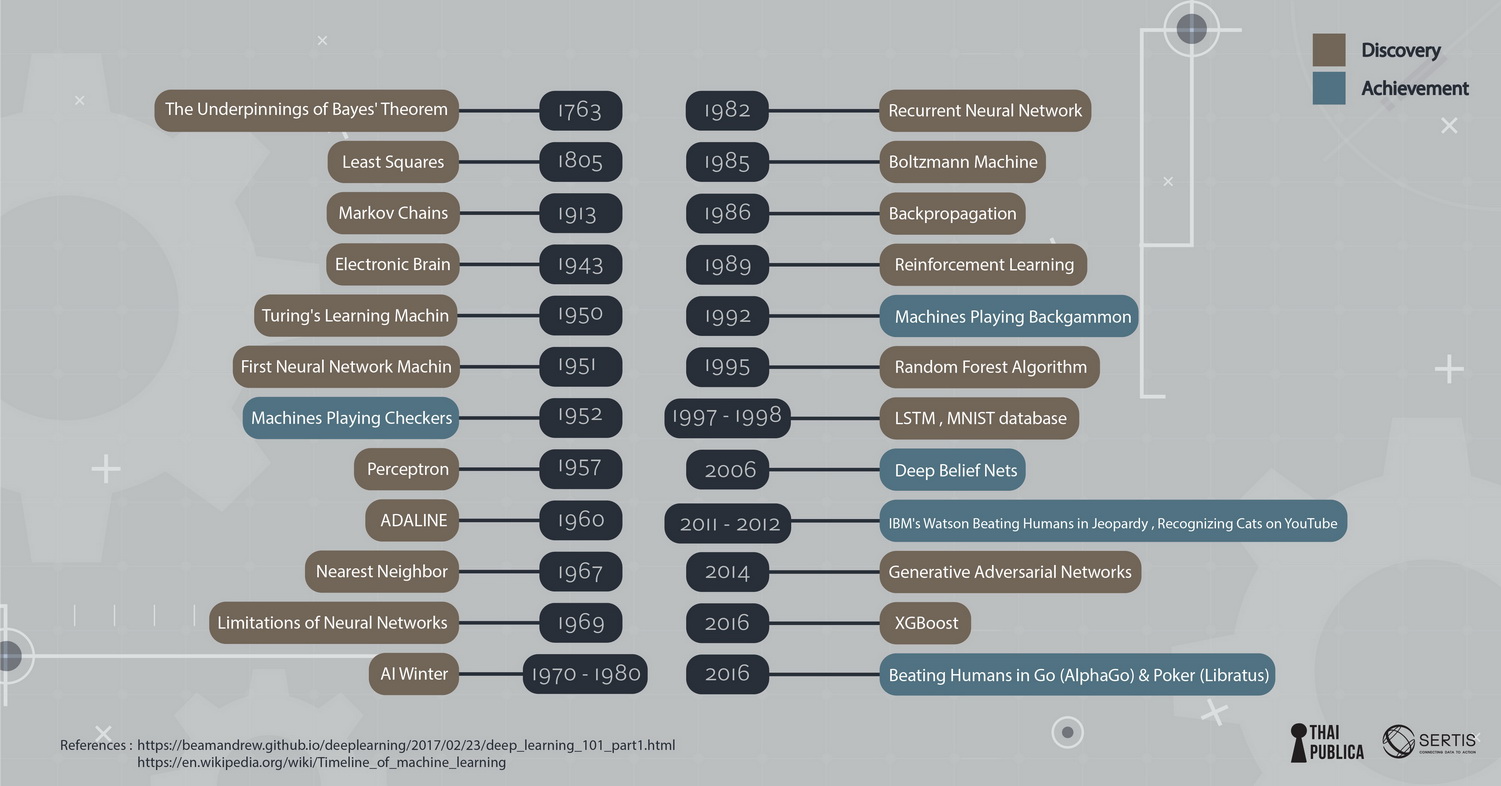
c.ถ้าเป็น model ที่เรียนรู้ด้วยการโต้ตอบกับสิ่งแวดล้อมโดยที่ไม่มีคำเฉลยให้เรียน เรียกว่า reinforcement learning เหมือนเด็กเรียนการเล่นเกมส์เล่นผิดเล่นถูกไปเรื่อยๆ จนเชี่ยวชาญขึ้น ตัวอย่างดังๆ ที่ใช้ model แบบนี้ก็คือ Google Alpha Go ที่ไปชนะนักเล่น Go หรือ href=”https://www.wired.com/2017/02/libratus/”>Libratus Poker AI ปกติแล้วเราจะใช้ model หลายๆ อย่างที่ data scientist คิดว่าน่าจะเหมาะกับ data เพราะ model ตัวเดียวไม่สามารถใช้ได้กับโจทย์ทุกอย่าง เพราะสมมุติฐานของ model ในโจทย์หนึ่งอาจใช้ไม่ได้กับโจทย์อื่น พอสมมุติฐานไม่ถูกต้องการทำนายก็ไม่ถูกต้อง (ในทาง ML เรียกหลักการนี้ว่า No Free Lunch Theorem) พอเราได้ candidate model (โมเดลที่น่าจะเหมาะสม) มาแล้วโดยทั่วไปเรามักจะเลือก model ที่ง่ายเพราะ model ที่ซับซ้อนมักจะมีความแปรปรวนสูง (variance) และจะปรับตาม training data มากเกิน (ทำให้เกิดอาการ overfitting เหมือนติวเพื่อสอบอย่างเดียวแต่ประยุกต์ไม่ได้) model ที่ง่ายมักจะประยุกต์ (generalize) กับ data ที่ไม่เคยเห็นได้ดีกว่า (เค้าเรียกหลักการเอา model ง่ายไว้ก่อน นี้ว่า Occam’s razor) ภาพที่ 5: ตัวอย่างของโมเดลที่ผิดพลาด ตัวอย่างวินาศภัยโรงงานพลังงานไฟฟ้านิวเคลียร์ Fukushima ในปี ค.ศ. 2011 (credit ตัวอย่างจาก ML@B Blog) เกิดจากความผิดพลาดของวิศวกรที่สร้าง model ที่ overfit เวลาที่ออกแบบโรงงานพลังงานไฟฟ้าวิศวกรต้องออกแบบเผื่อว่าจะมีแผ่นดินไหวบ่อยแค่ไหนโดยใช้สูตรของ Gutenberg-Richter Law ที่ทำนายความน่าจะเป็นของแผ่นดินไหวที่รุนแรงจากข้อมูลแผ่นดินไหวที่อ่อน (แทบจะไม่รู้สึกได้) ข้อมูลแผ่นดินไหวอ่อนมีมากเพราะเกิดขึ้นบ่อย วิศวกรใช้ข้อมูลแผ่นดินไหว 400 ปีที่ผ่านมาในการสร้าง regression model จากรูปจะเห็นว่าlog ของความน่าจะเป็นที่จะเกิดแผ่นดินไหวแปรตาม เป็นเส้นตรงตามขนาดความรุนแรงของแผ่นดินไหว (ข้อมูลรูปข้างล่างจุดดำเป็นข้อมูลในอดีต เส้นตรงเป็นเส้นที่ model ทำนาย) แต่วิศวกรโครงสร้างของโรงงานกลับ overfit ข้อมูล (รูปที่ 1) ปรับตามข้อมูลมากเกินไปแทนที่จะใช้สูตรของ Gutenberg-Richter Law เลยทำให้ทำนายว่า แผ่นดินไหวขนาดความรุนแรงเบอร์ 9 จะเกิดขึ้นทุกๆ 13,000 ปีขณะที่ model ที่ถูกต้องตาม Gutenberg-Richter Law ทำนายว่าแผ่นดินไหวขนาดความรุนแรงเบอร์ 9 จะเกิดขึ้นทุกๆ 300 ปี เพราะฉะนั้นโรงงานก็ถูกสร้างเพื่อทนความรุนแรงแค่ 8.6 แต่พอแผ่นดินไหวความรุนแรงเบอร์ 9เกิดขึ้นในปี ค.ศ. 2011 โรงงานก็ไม่สามารถรองรับความรุนแรงและเกิดความเสียหายอย่างน่าสลด model ที่ overfit อาจก่อให้เกิดความผิดพลาดได้อย่างตัวของ Fukushima ในทางตรงกันข้าม model ที่ underfit ก็เป็น model ที่ทำนายไม่แม่นเพราะตัว model อาจจะไม่เหมาะสมกับ data หรือ model ไม่สามารถหา pattern เพื่อใช้ในการทำนายได้ (ดูภาพที่ 6) ภาพที่ 6: ตัวอย่างของโมเดลรูปแบบต่างๆ สิ่งที่สำคัญที่สุดของ ML คือการประยุต์ใช้ (generalization) สิ่งที่ model เรียนมากับข้อมูลชุดใหม่ เพราะฉะนั้นไม่เพียงใช้แค่ data แต่ต้องใช้ความรู้ที่มีอยู่(สมมุติฐานของ model) ในการ generalize หรือเขียนเป็นหลักการสมการว่า Generalization = Data + Knowledge Generalization เป็นสิ่งที่มนุษย์ทำได้ดีกว่าเครื่อง เรามีความสามารถที่จะประยุกต์ใช้ความรู้กับโจทย์ใหม่ๆได้ดี ในขณะที่เครื่องยังพยายามเลียนแบบสมองคนแต่ก็ยังทำได้เป็นงานเฉพาะทาง ภาพที่ 7: สรุปประวัติศาสตร์ของ Machine Learning ถ้าดูจากประวัติศาสตร์ของ Machine Learning จนถืงปัจจุบัน จะเห็นวิวัฒนาการที่จะทำให้เครื่องเรียนรู้งานต่างๆ เทียบเท่าหรือดีกว่ามนุษย์ เริ่มตั้งแต่ Bayes theorem ซึ่งเป็นทฤษฎีพื้นฐานที่ใช้ใน AI (ความน่าจะเป็นที่เหตุการณ์จะเกิดขึ้นกับความเชื่อที่มีอยู่ prior belief กับข้อมูลที่สังเกตเห็น evidence/data) การคิดวิธี least square เพื่อมาใช้ fit data มาจนถึงการจำลองเหตุการณ์ด้วย markov chain ซึ่งนำไปประยุกต์ใช้ได้หลายด้าน (สร้าง model ในการพูด การใช้ภาษา) สิ่งที่สังเกตเห็นได้จากวิวัฒนาการก็คือความพยายามหาแบบจำลองที่มีความใกล้เคียงกับสมองมนุษย์ จนมาถึงช่วงปี ค.ศ. 1970-1980 ซึ่งเป็นช่วง AI มาถืงจุดตัน (ที่เรียกว่าช่วง AI winter) เมื่อ Minsky เขียนหนังสือ Percentrons ที่แสดงให้เห็นว่า perceptron (ซึ่งเป็น model พื้นฐานที่นำมาใช้กับ neural networkได้) ไม่สามารถเรียนรู้ function ง่ายๆ อย่าง XOR ซึ่งเป็นการทำลายความหวังของงานวิจัยทาง neural network model ที่กำลังได้รับความสนใจ Neural network กลับมามีความหวังอีกครั้งในช่วงปี ค.ศ.1986 เมื่อ David Rumelhart (กล่าวถึงในตอนที่แล้ว), Ronald Williams, Geoff Hinton ตีพิมพ์ผลงานวิจัย “Learning representations by back-propagating errors” ซึ่งแสดงให้เห็นว่าการเพิ่มจำนวน layer ข้างใน neural network ช่วยทำให้เรียนรู้ได้ดีขึ้นและแก้ปัญหาทางตันที่ Minsky หยิบยกขึ้นมาได้ ซึ่งทำให้งานวิจัยทาง neural network กลับคืนชีวิตขึ้นมาอีกครั้ง ยิ่งในช่วงเกือบ 10 ปีที่ผ่านมาเครื่องมีความสามารถสูงขึ้น การเข้าถึงผ่าน cloud computing การใช้ GPU ที่ใช้ในงาน Graphics มา train model (เพราะ GPU สามารถคำนวณเลข matrix ได้อย่างรวดเร็ว) ข้อมูลในโลก internet ที่มีมากขึ้นบวกกับ algorithm ใหม่ๆ ในการ train neural network ที่มีประสิทธิภาพดีขึ้น ทำให้ deep learning model (ซึ่งก็คือ neural network model ที่มีความซับซ้อนมีการนำมาเชื่อมเป็นหลายๆ ชั้น) เริ่มเป็นที่นิยมมากขึ้นเพราะเป็น model ที่ทำงานได้ดีกับข้อมูลขนาดใหญ่เช่น ข้อมูลภาพ video เสียง text model ทาง deep learning เริ่มมีการพัฒนาอย่างรวดเร็ว มี model ที่ใหญ่และซับซ้อนมากขึ้น เช่น An Analysis of Deep Neural Network Models for Practical Applications ถ้าถามผมว่าการเรียนรู้หรือการ train model เหมือนสิ่งที่มนุษย์ทำไหมผมก็อาจตอบได้ว่าต่างกันมาก ครั้งหน้าผมจะมาเปรียบเทียบให้คุณผู้อ่านได้เห็นความแตกต่างของการ train ระหว่างเครื่องกับมนุษย์ว่าต่างกันอย่างไร