สฤณี อาชวานันทกุล
สองตอนที่ผ่านมาผู้เขียนพูดถึงกลไกกำกับสื่อสองระดับ คือ “กลไกกำกับดูแลร่วมกัน” หรือ co-regulation ซึ่งเห็นว่าควรจะนำมาใช้กับสื่อมวลชนกระแสหลักที่ประกอบการภายใต้ใบอนุญาตจาก กสทช. เนื่องจากใช้คลื่นความถี่อันเป็นสมบัติสาธารณะ กับ “กลไกกำกับดูแลกันเอง” หรือ self-regulation ซึ่งสื่อต่างๆ ทุกประเภท ไม่ว่ากระแสหลักหรือกระแสรอง สื่อใหม่หรือสื่อเก่า สามารถใช้เป็น “ด่านแรก” ในการกำกับเนื้อหาที่ไม่ถึงขั้นผิดกฎหมาย แต่ผิดจริยธรรมสื่อ โดยไม่ต้องถึงมือรัฐ
ในเมื่อสื่อใหม่และสื่อเก่าจำนวนนับไม่ถ้วนวันนี้ใช้อินเทอร์เน็ตเป็นพื้นที่ในการทำงานและสื่อสาร และในเมื่ออินเทอร์เน็ตขับเคลื่อนด้วย “โค้ด” (code) คอมพิวเตอร์ ก็ไม่น่าแปลกใจที่ “โค้ด” จะสามารถเป็นหนึ่งในกลไกกำกับดูแลกันเองของสื่อ โดยเฉพาะสื่อแบบโซเชียลมีเดียซึ่งเดินด้วยเนื้อหาที่ผู้ใช้สร้างเอง หรือ user-generated content เป็นหลัก
ในคอลัมน์นี้เมื่อปีกลาย ผู้เขียนเคยพูดถึงวิธีจัดการกับเนื้อหาที่สุ่มเสี่ยงว่าจะก่อให้เกิดความเกลียดชังถึงขั้นใช้ความรุนแรง หรือ “เฮทสปีช” ของเฟซบุ๊ก (Facebook) โซเชียลมีเดียยักษ์ใหญ่มาแล้ว โดยเอกสารที่หลุดมาถึง SZ หนังสือพิมพ์ฉบับหนึ่งในเยอรมนี ทำให้เรารับรู้ว่า วิธีจัดการกับเนื้อหา “เฮทสปีช” ของเฟซบุ๊กนั้นใช้ “คน” ผสมกับ “โค้ด” เริ่มต้นจากการนิยาม “ประเภทคุ้มครอง” (protected category) ก่อน เช่น เด็ก ศาสนา ผู้ชรา ฯลฯ แต่เส้นแบ่งนี้ก็พร่าเลือนเมื่อมาถึงกลุ่มใหม่ๆ ซึ่งตกเป็นเป้าของเฮทสปีชเมื่อไม่นานมานี้ เช่น ผู้อพยพ (migrants)
รายงานข่าวของ SZ ระบุว่า “ยกตัวอย่างเช่น [ใครก็ตามจะ]โพสว่า “มุสลิมเหี้ยๆ” (fucking muslims) ไม่ได้ เพราะการสังกัดศาสนาใดศาสนาหนึ่งเป็นประเภทคุ้มครอง แต่ประโยค “ผู้อพยพเหี้ยๆ” โพสได้ เพราะผู้อพยพเป็นเพียง “ประเภทกึ่งคุ้มครอง” (quasi-protected category) – ประเภทพิเศษซึ่งเฟซบุ๊กกำหนดขึ้นมาใหม่หลังจากที่ถูกร้องเรียนในเยอรมนี กฎข้อนี้บอกว่า การส่งเสริมความเกลียดชังต่อผู้อพยพนั้นทำได้ภายใต้บริบทบางอย่าง ประโยคอย่าง “ผู้อพยพสกปรกโสโครก” (migrants are dirty) ไม่ผิด แต่ “ผู้อพยพเป็นขี้ตีน (migrants are dirt) ผิด”
นอกจากเฟซบุ๊กจะต้องตอบสนองต่อข้อร้องเรียนและเสียงเรียกร้องจากผู้ใช้อย่างต่อเนื่องแล้ว เฟซบุ๊กก็มอบอำนาจให้ผู้ใช้กำกับดูแลกันเองในบางระดับด้วย
ยกตัวอย่างเช่น ตั้งแต่ปี 2011 เป็นต้นมา เฟซบุ๊กเพิ่มฟังก์ชั่นให้ผู้ดูแลเพจ (Facebook page admin) สามารถเพิ่มรายการคำศัพท์ที่ไม่ต้องการให้แสดงบนเพจ (moderation blocklist) เช่น ถ้าหากเราเป็นผู้ดูแลเพจที่ไม่อยากเสี่ยงต่อการถูกแกล้ง มาโพสความเห็นที่มีข้อความหมิ่นเหม่ว่าจะผิดกฎหมายอาญา มาตรา 112 (หมิ่นพระบรมเดชานุภาพ) พ่วงมาตรา 14 พ.ร.บ. คอมพิวเตอร์ หลังจากที่ลบข้อความนั้นไปแล้ว เราก็สามารถไปเพิ่มคำคำนั้นลงใน moderation blocklist ได้ ครั้งต่อไปที่มีคนมาโพสคำคำนี้ ข้อความจะถูกโค้ดของเฟซบุ๊กซ่อนไว้ ไม่แสดงต่อสาธารณะ และถูกจัดว่าเป็น “สแปม” โดยอัตโนมัติ
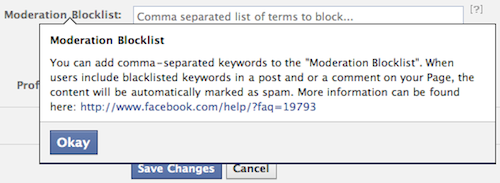
นอกจาก moderation blocklist เฟซบุ๊กยังมี “รายการคำหยาบ” (profanity blocklist) รวบรวมคำที่ถูกร้องเรียนจากชุมชนผู้ใช้บ่อยครั้งจนเฟซบุ๊กตัดสินใจแบนเอง ในฐานะผู้ดูแลเพจ เราสามารถเลือกได้ว่าจะกรองคำหยาบแบบ “ปานกลาง” (medium) หรือ “เข้ม” (strong) (อ่านรายละเอียดของ moderation blocklist และ profanity blocklist ได้ที่หน้านี้ของเฟซบุ๊ก)
ไม่เพียงแต่เฟซบุ๊กที่ใช้ “โค้ด” ผสมกับการตัดสินใจของ “คน” ในการกำกับเนื้อหา บริษัทผู้ให้บริการยักษ์ใหญ่อีกหลายเจ้าก็มีวิธีคล้ายกัน เช่น กูเกิล (Google) ทำรายการคำหยาบ (“bad words”) และใช้เป็นค่าตั้งต้นในการค้นหา (หรือพูดในภาษากูเกิลได้ว่า ฟังก์ชั่น “SafeSearch” ทำงานตลอดเวลา) หน้าเว็บไหนมีคำใดคำหนึ่งในรายการนี้ โค้ดของกูเกิลจะไม่แสดงหน้าเว็บนั้นๆ ในผลการค้นหา
ฉะนั้น ถ้าหากเราอยากให้คนค้นเจอหน้าเว็บเราจากกูเกิล (ใครบ้างจะไม่อยาก!) เราก็จะต้องดูแลไม่ให้คำเหล่านี้ปรากฎบนเว็บเลย
(กูเกิลไม่เคยเปิดเผย “รายการคำหยาบ” ที่ว่านี้ต่อสาธารณะ แต่จากการแลกเปลี่ยนข้อมูลระหว่างผู้ใช้เน็ต ก็มีคนทำรายการนี้ขึ้นมาเอง สามารถดาวน์โหลดได้จากบล็อกนี้)
กรณีการใช้ “โค้ด” กำกับเนื้อหาล่าสุดคือ วิธีจัดการกับ “ข่าวปลอม” ซึ่งผู้เขียนก็เคยพูดถึงในคอลัมน์นี้ไปแล้วเช่นกัน โดยเล่ากรณีที่เฟซบุ๊กออกมาประกาศต่อสาธารณะกลางเดือนธันวาคม 2559 ว่า เฟซบุ๊กได้ออกมาตรการมาแล้ว 4 อย่าง เพื่อจัดการกับปัญหา “ข่าวปลอม” ได้แก่
1. ปรับฟีเจอร์ให้ผู้ใช้รายงานข่าวปลอมได้ง่ายขึ้น โดยถ้าคลิกที่มุมด้านขวาของทุกโพสจะขึ้น “นี่เป็นข่าวปลอม” เป็นทางเลือกในเมนูการรายงานเนื้อหาที่ไม่เหมาะสม
2. ทำงานร่วมกับองค์กรที่มีชื่อเสียงในด้านการตรวจสอบข้อเท็จจริง เช่น Snopes.com, Factcheck.org และ Politifact เพื่อตรวจสอบว่าข่าวแต่ละชิ้น “จริง” หรือไม่ ถ้าหากองค์กรเหล่านี้ “ติดธง” ว่าข่าวชิ้นนั้นมีปัญหา เฟซบุ๊กจะขึ้นคำว่า “มีปัญหา” (disputed) ให้เห็นในนิวส์ฟีด แสดงลิงก์ไปยังบทความอธิบายบนเว็บไซต์ขององค์กรที่เช็คข่าวชิ้นนั้นๆ และอัลกอริธึมหรือโค้ดของเฟซบุ๊กจะ “ลดคะแนน” ข่าวชิ้นนั้นให้แสดงผลในนิวส์ฟีดต่ำกว่าข่าวชิ้นอื่นๆ แต่จะไม่ถึงกับลบข่าวชิ้นนั้นออกจากเฟซบุ๊ก
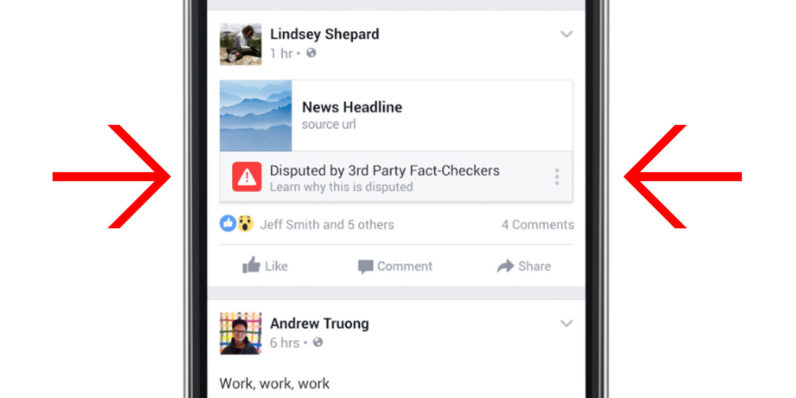
3. ปรับโค้ดของเฟซบุ๊กในการจัดอันดับข่าวในนิวส์ฟีดใหม่ โดยใช้ข้อมูลจากชุมชนผู้ใช้เฟซบุ๊กเอง เช่น ถ้าข่าวชิ้นไหนมีการแชร์น้อยมากหลังจากที่คนเข้าไปอ่าน ก็อาจเป็นสัญญาณว่ามันมีปัญหาอะไรบางอย่างหรือทำให้คนเข้าใจผิด เฟซบุ๊กจะปรับอันดับของข่าวทำนองนี้ให้อยู่ต่ำกว่าปกติในนิวส์ฟีด
4. บั่นทอนแรงจูงใจทางเศรษฐกิจ – คนจำนวนมากแกล้งทำสำนักข่าว โพสข่าวปลอมบนเฟซบุ๊กเพื่อล่อหลอกให้คนตามไปอ่านบนเว็บไซต์ของพวกเขา แล้วก็ทำเงินจากโฆษณาบนเว็บ เฟซบุ๊กเริ่มจัดการกับปัญหานี้ด้วยการกำจัดความสามารถในการปลอมโดเมนเนม (spoof demain) เพื่อลดจำนวนเว็บไซต์ที่ “อำพราง” ว่าตัวเองเป็นสำนักข่าวจริง และปรับปรุงนโยบายขายพื้นที่โฆษณาว่า “ข่าวปลอม” จัดเป็น “เนื้อหาที่หลอกลวงและทำให้คนเข้าใจผิด” ซึ่งเฟซบุ๊กไม่รับโฆษณาให้
จะเห็นว่าวิธีจัดการกับ “ข่าวปลอม” ของเฟซบุ๊กข้างต้นนั้น ล้วนแต่เป็นส่วนผสมระหว่าง “โค้ด” (เช่น ติดป้ายเตือนว่าอาจเป็นข่าวปลอม) กับ “คน” (เช่น ให้ทีมผู้เชี่ยวชาญด้านการจับเท็จมาช่วยวิเคราะห์เนื้อหา) ทั้งสิ้น
ทำให้ผู้เขียนนึกถึงปี 2013
รอส ลาเจอเนสส์ (Ross LaJeuNesse) ตำแหน่ง Global Head of Free Expression and International Relations ของกูเกิล ไม่รู้จะแปลเป็นไทยว่าอะไรดี ใกล้เคียงที่สุดอาจเป็น “หัวหน้าฝ่ายเสรีภาพในการแสดงออกและความสัมพันธ์ระหว่างประเทศ” ซึ่งการที่กูเกิลมีฝ่าย Free Expression ก็เป็นเครื่องยืนยันระดับหนึ่งว่ากูเกิลเอาจริงกับเรื่องนี้ขนาดไหน
ถามว่าเขามี “มาตรฐาน” ในการทำตามหรือไม่ทำตามคำสั่งของรัฐบาลประเทศต่างๆ อย่างไร เวลาที่รัฐบาลขอให้เซ็นเซอร์เนื้อหา เขาตอบว่าที่จริงขึ้นอยู่กับแต่ละบริการของกูเกิล ว่าแล้วก็ลุกขึ้นไปวาดแผนผังให้ดูบนผนัง ผู้เขียนลอกและสรุปความมาได้ประมาณนี้ น่าสนใจไม่น้อย –

อีกตัวอย่างของการใช้ “โค้ด” กำกับเนื้อหาในเน็ต คือ เมื่อเดือนพฤษภาคม 2011 เฟซบุ๊กประกาศใช้เทคโนโลยี “Photo DNA” ของไมโครซอฟต์ เพื่อช่วยเจ้าหน้าที่รัฐปราบปรามสื่อลามกอนาจารเด็ก ตามจับผู้ที่ทำทารุณกรรมเด็กหรือลักพาตัวเด็ก ซึ่งทั้งหมดนี้ผิดกฎหมาย ขณะที่สื่อลามกเด็กแพร่หลายอย่างรวดเร็วบนเน็ต ผู้ทำและเผยแพร่มักหลบเลี่ยงการตรวจจับด้วยการดัดแปลงรูปถ่ายทีละน้อย ทำให้จับยากมากเพราะไม่ใช่สำเนาที่เหมือนกับต้นฉบับ 100%
เทคโนโลยี Photo DNA แก้ปัญหานี้ด้วยการสร้าง “ลายเซ็น” ที่เป็นเอกลักษณ์ของรูปถ่ายแต่ละใบขึ้นมา คล้ายกับลายนิ้วมือของคน ทำให้รู้ว่ารูปถ่ายใบไหนเป็นสำเนาของใบอื่น แม้มันจะถูกเปลี่ยนขนาดหรือดัดแปลงไป ทำให้ค้นหารูปถ่ายลามกเด็กในบรรดารูปนับล้านได้อย่างง่ายดายกว่าเดิมมาก เฟซบุ๊กเป็นบริษัทแรกที่ประกาศใช้เทคโนโลยีนี้ และก็นับว่านี่เป็นก้าวสำคัญในการต่อสู้กับผู้ประสงค์ร้ายที่ใช้เทคโนโลยีอินเทอร์เน็ตในทางที่ผิด
ปัจจุบันเทคโนโลยีนี้ถูกใช้อย่างแพร่หลายและมีหลักฐานว่ามีประสิทธิภาพ ในสหรัฐอเมริกาประเทศเดียว เจ้าหน้าที่สามารถตามหาและช่วยชีวิตเด็กได้กว่า 1,000 คน เพียงปีเดียวคือ 2016 ด้วยเทคโนโลยี PhotoDNA
นับเป็นตัวอย่างอันดีของการใช้โค้ดสนับสนุนค่านิยมและจับกุมผู้กระทำผิดกฏหมาย โดยไม่ไปละเมิดสิทธิของผู้บริสุทธิ์ เช่น ห้ามคนอัพโหลดรูปใดๆ เลย เพียงเพราะหนึ่งในพันเป็นรูปลามกเด็ก
ตัวอย่างเหล่านี้ชี้ว่า “โค้ด” สามารถเป็นกลไกกำกับเนื้อหาที่มีประสิทธิภาพ และไม่ลิดรอนสิทธิเสรีภาพเกินระดับที่ “จำเป็นและได้ส่วน” ได้ ถ้ามันถูกออกแบบมาอย่างถูกต้องเหมาะสมและสอดคล้องกับประเด็นที่สังคมกังวล
คำถามต่อไปคือ นอกจากจะเรียกร้องให้บริษัทอินเทอร์เน็ต “โค้ด” ให้ดีขึ้น คนใช้เน็ตทำอะไรได้อีก?
โปรดติดตามตอนต่อไป.